公认的计算机之父是阿兰·图灵在 1936 年提出了「图灵机」的概念。图灵机是一个抽象的计算模型,它可以形象地表述为:
- 有一个向两端无限延伸的带子,可以在上面记录内容
- 有一个可以在带子上擦除/写入的读写头,可以在带子上任意移动
- 有一个控制器,控制读写头的移动和擦除/写入操作
图灵机的表述看似纸上谈兵,但实际与现在计算机的体系结构有良好的对应,甚至可以说是所有现代计算机背后的灵魂。
- 带子对应于内存(当然内存不能无限大,这限制了计算机的处理能力是有上限的)
- 读写头可以在带子上任意移动读写对应内存的随机存取(内存的英文名字就是 Random Access Memory)
- 控制器对应中央处理器
在内存这条带子上,找到正确的位置以便进行存取的过程,就是所谓的「内存寻址」过程。在图灵机这个思想模型中,我们可以假设读写头可以按照要求立即在带子上找到正确的位置。但是在现实生活中,有效地内存寻址是必须要解决的问题。因此,内存寻址可谓是计算机体系结构的核心问题之一。
这篇文章主要讨论 Intel x86 架构上的内存寻址问题。纯干货,吃到撑。
基本概念
物理内存和物理地址
物理内存指的就是那些看得见摸得着的内存条实际提供的内存空间。
在文章开头处,我们说「在内存这条带子上,找到正确的位置以便进行存取的过程,就是所谓的『内存寻址』过程」。既然有所谓的「正确的位置」,那么就必然有一个描述位置的方法。在内存空间中描述位置的方法,就是内存地址。
对于物理内存来说,我们将它的内存空间按照字节(Byte, 1 Byte = 8 bit)划分开来,并从 0 开始将它们标上号。这些无符号的整数编号,就是物理内存地址。物理地址和地址总线上传输的地址一一对应。
如果正在运行的程序,能够直接通过物理地址操作物理内存,那么写这种代码的方式被称为「硬编码」。在硬编码的情形下,内存寻址的任务最简单:只需要拿着硬编码得到的地址,输进地址总线去访问内存就可以了。
线性内存和线性地址
上节提到,物理内存按照字节划分开来,并从 0 开始编号,逐渐增大。这个增大的过程是线性的。
线性内存和物理内存类似,它的地址编号也是从 0 开始,线性增加。线性地址和物理地址的不同在于:
- 物理地址总是一一对应于实际物理内存空间的位置;但是线性地址则不一定这样:可以有多个线性地址对应到一个物理地址上。
- 物理地址的增加,总是线性地对应着内存空间的位置;但是线性地址的增加,对应到物理地址上,可以分段跳跃。
逻辑内存(虚拟内存)和逻辑地址(虚拟地址)
现代的内存寻址机制,都引入了名为「分段」的概念:不同级别的程序、程序的不同数据类型,存放在不同的「段」上面,然后再定义在「段」上的偏移量。也就是说,现代程序看到的地址都不是线性的,而是分段过的地址,形如:segment:offset。
这些段和偏移量组成的空间,就是逻辑内存空间;这些二元组,就是逻辑地址。
逻辑内存经过转换得到的地址,如果是线性地址,就说明当前机器开启了内存分段机制和分页机制;如果是物理地址,那就说明当前机器只开启了内存分段机制。
宽度
计算机体系结构中讲到的宽度,也称位宽,讲的是某个东西在同一时刻能够处理的数据的量。它的单位是数学中数字的「位」;现代计算机是以二进制为基础的,所以它的单位准确来说是「二进制的位数」。
上面提到的「处理」这一动作,根据讨论的对象的不同可能会发生改变。
比如,对于 CPU 中负责进行二进制算数运算的算术逻辑单元(Arithmetic Logic Unit, ALU)来说,它的处理就是进行二进制数的算术运算(二进制的加减乘,不包括除)。于是,如果一个 ALU 能够同时处理 4 bit 数据,也就是能一次计算 4 bit 二进制数的加减乘法,那么它就是一个 4 位的 ALU。对于 CPU 来说,ALU 的位宽也叫字长。
又如,对于负责 CPU 和北桥芯片(Northbridge Chip)的数据传递的前端总线(Front Side Bus, FSB)来说,它的处理就是传递二进制数据。于是,如果一条 FSB 能够一次性传输 8 bit 的数据,那么它就是一条 8 位的 FSB。对于总线来说,位宽也叫带宽。
CPU 的寻址能力浅说
这一小节提到的寻址能力,都以 Byte 为单位:亦即在不讨论内存分页的情况下,进行寻址能力的讨论。
对于 $x$ 位 CPU 来说,它一次性能够表示的无符号数的范围是 $ [0, 2^{x} - 1] $。因此,对这枚 CPU 来说,它以字节(Byte)为单位寻址时,最多能在 $2^{x} \text{ Bytes}$ 的内存空间中找到它需要的数据。如果在寻址时,不加入其它信息,那么这是它的寻址能力上限。
CPU 需要通过地址总线去内存寻址。若地址总线的带宽为 $y$ 位,那么在地址总线中传输的物理内存地址的范围是 $ [0, 2^{y} - 1] $。也就是说,地址总线的可寻址空间是 $2^{y} \text{ Bytes}$。地址总线中的地址,是与物理内存地址保持一致的。
因此,如果在寻址时,不加入其它信息,CPU 具体的寻址能力取决于 CPU 本身的位宽和它连接的地址总线的带宽:$2^{\min(x, y)} \text{ Bytes}$。
值得一提的是,二进制数据在计算机内部用电信号表示,每一位二进制,就需要一份电信号。这就是说,在不考虑复用的情况下,$x$ 位的 CPU 需要 $x$ 个引脚与前端总线相连;$y$ 位的地址总线又需要 $y$ 个引脚。因此这枚微处理器的引脚个数必然不小于 $ x + y $。
硬编码的寻址
世界上第一款 CPU 是 Intel 公司于 1971 年 11 月 15 日发布的 4004 微处理器。这是一款 4 位的处理器,地址总线的带宽是 12 位的(4004 的引脚个数正是 16 针),能够使用 640 Bytes 的内存。
随后,Intel 公司在 1974 年 4 月发布了 8080 微处理器。这是一款 8 位处理器,它有 7 个累加器:ABCDEHL。其中 A 是主累加器,其余的是次累加器。而次累加器可以配对,比如配对成 BC 或者 HL。两个 8 位的次累加器配对,可以表示 16 位的二进制数。据此,8080 可以访问 $ 2^{16} = 64 \text{ KiB}$ 的内存空间。
这两款 CPU 没有任何分段或分页的概念,都使用的是硬编码的方式去寻址。因此,当 CPU 接收到进程的访存请求后,直接将请求地址传入地址总线,然后去存取内存。可谓是简单粗暴。
实模式与内存分段初步
1976 年 3 月,Intel 公司发布了 8086 微处理器,并搭配了 20 位的地址总线。因此,从地址总线的角度来说,8086 应当可以访问 1 MiB 的内存空间。不过,尴尬的是,8086 的 ALU 是 16 位的,也就是它是一个 16 位的处理器。
为什么要用 20 位这么「奇怪」的数字呢?原因有两个:一是当时要凑 1 MiB 的内存,所以地址总线至少得有 20 位的带宽;二是限于当时技术,造不出多于 40 个引脚的 CPU,又因为没有复用技术,所以搭配 16 位 CPU 的话,地址总线带宽最多是 24 位。所以最终就确定了 20 位的地址总线。
好了,再看到之前我们对 CPU 寻址能力的分析,我们就知道:这种时候,必然要引入额外的信息。Intel 将它称之为「内存分段(Segment)」。
具体做法是引入 4 个 16 位的段寄存器:CS, DS, SS 和 ES,分别用来存储程序的代码段、数据段、堆栈段和其他段。具体访问内存的时候,将相应的段寄存器的值左移 4 位,与 CPU 产生的 16 位访存地址相加,这样就得到一个 20 bit 的地址。这种带有分段的寻址模式,叫做实模式(Real Mode)。
举个栗子。假设 ES = 0x1000, DI=0xffff。那么,ES:DI 对应的物理地址就是:AD = ES * 0x10 + DI = 0x1ffff。
对于程序员来说,在采用这种寻址方式的 CPU 上编程时,只需要知道 CPU 的访存地址,不需要去计算 20 位的物理地址——硬件在底层会自动操作。也就是说,程序在运行的时候,进程内部只需要处理一个线性的 offset 即可,至于段基址,依靠操作系统在程序执行时绑定就好。这样一来,程序员在编程时就不需要「硬编码」了,调试和内存相关的错误,也更容易定位了;另一方面,对于编译器来说,也是一种解脱。
问题就此解决了吗?并没有……
我们知道,20 位的寻址空间,能够表达的地址范围是 0x00000 -- 0xfffff。然而,用实模式寻址,最高能够得到的地址是 0xffff + 0xffff = 0x10ffef。这超出了寻址总线 20 位带宽允许的寻址空间的上限,但在逻辑上却完全正常,这就产生了矛盾。为了解决这个问题,Intel 引入了被称为 Wrap-around 的技术。这一技术是说,当实模式寻址的时候,如果需要访问实际不存在的 0x100000 -- 0x10ffef 范围内的物理内存时,对求得的物理地址用 0xfffff 取模。也就是说,Intel 将上述范围的地址,映射到 0x00000 -- 0x0ffef 上去。
不过,实模式虽然分段,但是只要获取到段寄存器中的地址,任何程序都可以直接操作内存读写。这就产生了两个显而易见的风险:
- 应用程序可以直接修改内存中的数据,甚至是操作系统的数据。因此,一旦应用程序把内存写烂了,那么整个系统就会立即挂掉。
- 第二个风险是第一个风险的扩展。因为应用程序可以直接修改内存中的数据,所以应用程序互相之间可能产生干扰。因此,实模式下,程序的安全性无法得到保证,操作系统无法支持多任务。
此外,具体到一个物理地址上,可以有多种不同的表示方式。例如,0x0001:0x0000 和 0x0000:0x0010 都表示的是 0x00010 这个物理地址。这种歧义性,也会带来一些难以控制的风险。
保护模式和内存分段进阶
Intel 在 1982 年 2 月发布了它的进化版:80286 (iAPX 286)。80286 和 8086 一样,也是 16 位 CPU,不过搭配的地址总线则上升到了 24 位。因此它可以支持最大 16 MiB 的内存空间。
80286 引入了保护模式。在这种模式下,CPU 够对内存及一些其他外围设备做硬件级的保护设置(实质上就是屏蔽一些地址的访问)。特别地,在访问内存时,程序不能从段寄存器直接获得段的起始地址(段基地址)了,而要进行额外的转换和检查。
具体来说,保护模式中:
- CPU 的访存地址与 8086 一样,仍旧是 16 位。这意味着,每个内存段的大小上限依旧是 64 KiB。
- 段寄存器的位宽与 8086 的段寄存器一样,也依然是 16 位。不过,80286 的段寄存器中存放的不在是段基地址,而是一个被称为选择器(Selector)的数据 struct。
- CPU 根据选择器中记录的数据,在描述符表(Descriptor Table,亦称段表)中找到段的详细信息,确定段基址和段地址上界,比对访问权级,成功后访问转为相应内存地址访问。
16 位选择器的具体组成如下:
- 0--1 位:访问权级(0 最高,3 最低)
- 2 位:段表类型
- 3--15 位:段表位置索引
其中,最低 2 位的访问权级是保护模式的核心内容,低权级的访存请求不能访问高权级的内存空间。描述符表类型是为了区分全局段表(Global DT, GDT)和进程自己维护的局部段表(Local DT, LDT)。段表的位置索引,则是指引 CPU 去访问段表,查找相应段的具体信息的无符号整数。
段表中的项的结构则比较复杂,不过最重要的信息,是段的起始地址(24 位),以及段的长度(16 位)。
不难看出,80286 引入的保护模式,与 8086 的实模式格格不入。为了 Intel 良好的「兼容传统」,80286 被制作成启动时继承了以前版本芯片的特性,工作在实模式下。这种模式实际上是关闭了新引入的的保护特性,因此过去的软件,可以继续工作在新的芯片下。后续的 x86 处理器都是在计算机加电启动时都是工作在实模式下,只能访问 1 MiB 的内存空间,而后切换到保护模式下。实际上,操作系统启动时最重要的几件事情之一,就是将 CPU 切换为保护模式。
因为 CPU 位宽限制,CPU 每次访存所要访问的物理地址为段表相应条目给出的 24 位段起始物理地址再加上 16 位的偏移量。可见,80286 保护模式下的应用程序能访问的内存线性地址空间仅为 64 KiB,非常有限。所以程序员编写使用大内存的应用程序时还必须使用远指针、近指针,相当繁琐。这种天生残废,影响了 286 保护模式的推广使用。
80386 的分段机制
相对于实模式,80286 引入的保护模式无疑是一大进步。然而,80286 的天生残疾,注定了它不会长久。
1985 年 10 月 17 日,Intel 发布 80386。386 是正儿八经的 32 位 CPU——它的 ALU 位宽是 32 位,同时地址总线带宽与此保持一致,也是 32 位的。做一个简单的计算,我们知道,386 的寻址能力已经能够达到 4 GiB。
386 的寄存器
在 8086 时代,为了强行寻址 1 MiB 的空间,16 位的 CPU 搭配 20 位的地址总线,不得不发明出内存分段的概念。在 80286 时代,依旧是 16 位的 CPU,但地址总线已经有 24 位。更加显著的差距,加上新引入的保护模式,在兼容的指导思想下,80286 的寻址模式被设计得更加复杂。
按说,80386 的 CPU 和地址总线都是 32 位的,内存寻址的方式应该可以变得十分简洁。然而很遗憾,依旧是「兼容思想」惹的祸,80386 必须兼容实模式,维护那些段寄存器。作为第一个 32 位 CPU,我们来看一下它相对于 16 位的 80286 的变化。
- 原 16 位的通用寄存器、标志寄存器以及指令寄存器,被扩充为 32 位。
- 增加 4 个 32 位的控制寄存器。
- 增加 4 个系统地址寄存器,两个 48 位的,另外两个是 16 位的。
- 增加 8 个 32 位的调试寄存器。
- 增加 2 个 32 位的测试寄存器。
- 段寄存器仍是 16 位;不过在数量上,除了原有的 4 个 CS, DS, SS 和 ES 段寄存器,还增加了 2 个段寄存器:FS 和 GS。
除了 6 个段寄存器,其他寄存器大都扩充到了 32 位甚至更高。唯二的两个 16 位的系统地址寄存器,也是因为分段的缘故,停留在了 16 位。这样的设计,想想当年 Intel 的设计师,估计脸都是黑的。
386 的描述符
与 286 一样,引入了保护模式的 386 不再于段寄存器中保存段基址(段的起始地址),而是保存 16 位的选择器;具体选择器的内容也和 286 完全一致。
与 286 不同的是,386 的描述符足有 8 字节(64 位),具体内容如下:
- 63 -- 56 位:段基址的 31 -- 24 位。
- 55 位:寻址粒度位(G)。当 G = 0 时,段长度以字节计算;当 G = 1 时,段长度以分页长度 4 KiB 计算。
- 54 位:默认操作数位(D)。当 D = 0 时,操作数为 16 位;当 D = 1 时,操作数为 32 位。
- 53 -- 52 位:强行置 0,留作向后兼容。
- 51 -- 48 位:段界限的 19 -- 16 位。
- 47 位:存在位(P)。当 P = 0 时,该段不存在于物理内存中;当 P = 1 时,该段存在于物理内存中。
- 46 -- 45 位:访问权级位(DPL)。与选择符的 0 -- 1 位对应,是保护模式的核心。
- 44 位:系统位(S)。当 S = 0 时,该段为系统段;当 S = 1 时,该段为用户程序的代码段、数据段或堆栈段。
- 43 -- 41 位:类型段。3 位类型段的含义,根据该段的种类(代码段或是数据段、堆栈段)有不同。
- 40 位:存取权限字节的访问位(A 位)。在分段而不分页的系统中,当该段被访问时,该位置 1;对于使用分页的系统,该段无意义。
- 39 -- 32 位:段基址的 23 -- 16 位。
- 31 -- 24 位:段基址的 15 -- 8 位。
- 23 -- 16 位:段基址的 7 -- 0 位。
- 15 -- 8 位:段界限的 15 -- 8 位。
- ** 7 -- 0 位**:段界限的 7 -- 0 位。
我们发现,描述符的前 5 字节相对规整,包含 24 位段基址,以及 16 位段界限。实际上,这正是从 286 的描述符继承而来的。描述符的第 7 字节(从 0 开始编号,最后一字节)存放的是段基址的最后 8 位;描述符第 6 字节的前 4 位,存放的是段界限的最后 4 位。这样一来,386 的段基址有 32 位,段界限则是 20 位。因此(参见寻址粒度 G 位),当以字节为单位寻址时,386 的内存分段,最大长度可以达到 1 MiB;而当以(后面将会介绍的)分页为单位寻址时,386 的内存分段,最大长度可以达到 4 GiB。这样一来,286 中令人吐血的「近指针」、「远指针」问题就不存在了。
如果我们把描述符中的内容,简单划分为三部分:段基址(Base)、段界限(Limit)和属性(Attribute),那么段表大致可以用下图所示的表格表示。
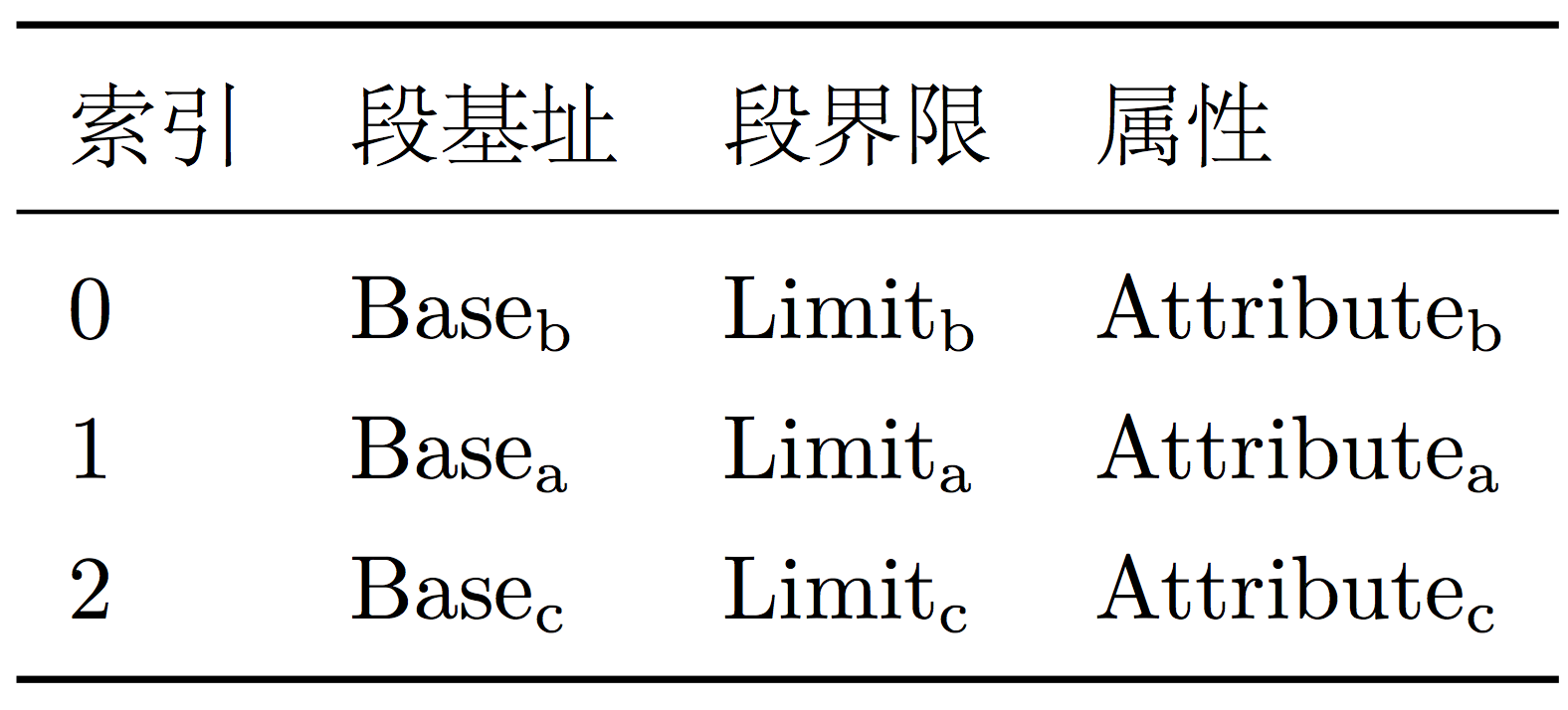
图中「索引」指的是选择器中的索引。
386 的段表
386 的段表定义了系统中所有段的情况。因为 386 的描述符占 8 个字节,所以 386 的段表的大小,按字节计算,总是 8 的整数倍。段表中,最少含有一个描述符,最多含有 8 Ki 个描述符(选择器的索引位是 13 位)。因此段表的大小应当居于 8 Bytes -- 64 KiB 之间。
386 将段表分为了 3 类:全局段表、局部段表和中断段表。全局段表,记录了除中断段表之外,其他所有任务公用的段的描述符;局部段表,则是每个任务都有一个,用于实现任务之间段层次的隔离;中断段表,对于程序员来说,不必太关心。
内存分页机制
这一节里,我们仍以 386 为例。
硬件中的内存分页
在介绍 386 的段描述符时,我们讲到描述符的第 55 位记录着分段内存的计算方式。当 G = 0 时,分页机制被禁用,逻辑地址经过分段机制转换出来的线性地址以字节计算;当 G = 1 时,分页机制启用,线性地址以分页长度计算。
那么什么叫分页呢?简单来说,分页就是人为地在逻辑上将连续的内存空间,按照固定大小切分成一段一段。对于线性内存来说,这样切分出来的固定大小叫做「页(Page)」;对于物理内存来说,这样切分出来的固定大小叫做「页帧(Page Frame)」。
因此,总结起来,分页机制将线性内存分为若干页,将物理内存分为若干帧,并建立从页到帧的映射关系。这个映射关系,是一个「多对一」的映射。
对于 386 来说,分页长度是 4 KiB。也就是说,对于一个 32 位的线性地址来说,它用末尾的 12 位表示分页内的偏移量。这 12 位的偏移量在页被映射到实际物理内存上的帧时,直接作为物理地址的末尾 12 位。至于线性地址的首 20 位,则作为从页映射到帧的编号参与映射计算。
页帧映射和页表
内存分页机制,主要解决的问题,就是当 CPU 取得一个线性地址时,如何将它映射到正确的物理地址上面。这个过程就是页帧映射。
显而易见,最简单的方式是建立一张足够大的表(称为页表):表中的 key 由线性地址的首 20 位计算得到(或者干脆就是它自己);表中的 value 则是对应页帧在物理内存中的起始地址(帧基址)。
这种情况下,我们假设极端的情况:每个进程都请求了 4 GiB 的线性空间。按照 4 KiB 每页计算,共需 1 M 个页帧信息。每份页帧信息至少包括 20 位的帧基址,再加上其他信息凑齐 4 Bytes。这样一来,每个进程的页表就需要 4 MiB 的空间。相对于需要高速数据交换的 CPU 来说,这个量太大了。在这种情况下,多级页表出现了。
二级页表
多级页表的原理和二级页表一样,所以这里以二级页表为例。
二级页表的原理是这样的:
- 维护一个大小为 4 KiB 的目录,称为页目录表(一级页表)。一级页表总共 1 Ki 项,对应线性地址的最高 10 位,每一项占 4 Bytes。每个进程在一级页表中对应一个表项,表项指向了进程实际二级页表的位置。
- 二级页表也是一个大小为 4 KiB 的映射表。二级页表同样一共有 1 Ki 项,对应线性地址中间的 10 位,其中每一项占 4 Bytes。表项记录了帧基址和其他一些控制信息。
高速缓存
这样一来,每次从线性地址转换为物理地址,就需要查表两次,每次交换 8 KiB 的数据。对于 CPU 高速频繁访存的操作来说,每次交换这么多数据无法满足性能要求。因此 386 增加了高速缓存机制。
高速缓存将最近的访存页面对应的内容保存其中。当 CPU 访存时,首先在缓存中查询是否有目标页内容:若有,则直接存取内容;否则,再进行二级页表的查询,到内存中存取内容。如果缓存存满了,则根据一定的算法(退场机制),将缓存中的过期数据退场。
根据 Intel 自己的统计,大约 98% 的访存请求可以通过高速缓存处理。亦即,只有 2% 的访存请求,需要进行两次页表查询。可见,高速缓存的存在,大大降低了数据交换的量和频次。因此,高速缓存大大提升了寻址/访存速度。
一级页表项
一级页表项占 4 字节,共 32 位。其中:
- 第 31 -- 12 位:20 位的页表地址。之所以可以用 20 位表示页表地址,是因为页表地址的低 12 位总是 0。
- 第 11 -- 9 位:留待操作系统使用。
- 第 8 位:总是置 0。
- 第 7 位:扩展分页标志(PSE)。PSE = 0 时,页大小为 4 KiB;PSE = 1 时,页大小为 4 MiB。
- 第 6 位:总是置 0。
- 第 5 位:访问位(A)。A = 1 时,说明当前项正在被访问。
- 第 4 位:高速缓存标志位(PCD)。PCD = 0 时,不启用高速缓存;PCD = 1 时,启用高速缓存。
- 第 3 位:高速缓存直写标志位(PWT)。PWT = 0 时,访存时只修改内存中的数据;PWT = 1 时,访存时同时修改内存和缓存中的数据。
- 第 2 -- 1 位:页保护位。
- 第 0 位:存在位(P)。当 P = 1 时,页对应的帧存在于物理内存中;当 P = 0 时,页对应的帧不存在与物理内存中。
值得一提的是,当 P = 0 时,访问该页将会引发一个「缺页错误」。操作系统内核会从交换空间(或者 Windows 的页面文件,都是访问速度更慢一级的硬盘)中交换数据到内存中去。这就是为什么,线性空间可以远远大于实际的物理内存空间的原因。
二级页表项
二级页表项同样占据 4 字节,共 32 位。二级页表项的高 20 位,存放的是帧基址;低 12 位的定义和内容含义与一级页表项完全相同;唯独区别在于一级页表项的第 6 位。
- 第 6 位:存取位(D)。当访存操作会修改内存中保存的内容时,该位置 1;否则置 0。
寻址空间的计算
讲清楚了选择符、描述符和段表,我们就以 386 的寻址方案,计算一下 CPU 最多能查找多大的内存空间。
首先,最底层的是描述符。描述符里,段界限占据了 20 位。当描述符粒度位 G = 1 时,段以分页大小 4 KiB 为单位寻址。因此一个描述符,最多能寻址 $2^{32}$ Bytes。
其次,16 位的选择器中,有 13 位用来记录描述符在段表中的索引位置。因此,一个段表可以有 $2^{13}$ 个描述符。
最后,在 16 位的选择器中,第 2 位记录的是段表类型(GDT 还是 LDT)。这样一来,寻址时可以有 2 个段表。
因此,386 的寻址方案,在不讨论扩展分页的情况下,最多能在 $2 \times 2^{13} \times 2^{32} = 2^{46}$ Bytes,也就是 64 TiB 的巨大空间中寻址。这个空间,因为它是从 0 开始编号,逐渐编号到 64 TiB 的,所以我们将它称为「线性空间」。这也就是说,在 386 的分段和分段机制的搭配下,它能够在 64 TiB 的线性空间中寻址。
实际寻址流程
当打开分页机制的 80386 接收到程序发来的访存请求 segment:offset 时,CPU 会……
- 读取段寄存器中的选择器;
- 验证访问权级(保护模式)——通过;
- 根据段表类型和段表位置索引,读取段表中的描述符;
- 检查访问权级位(保护模式)——通过;
- 检查
offset,看偏移量是否超过段界限; - 检查 P 位,确保目标位置在物理内存中可用;
- 将段基址与
offset拼接成线性地址; - 检查是否命中高速缓存——未命中;
- 根据线性地址最高 10 位,读取一级页表;
- 一级页表检查访问权级——通过;
- 得到 20 位 + 12 位补 0 的二级页表位置;
- 根据二级页表位置访问二级页表;
- 根据线性地址中间 10 位,读取二级页表;
- 二级页表检查访问权级——通过;
- 得到 20 位帧基址;
- 与线性地址的低位 12 位拼接成 32 位的物理地址;
- 访存。
x86 与 IA32
由于 80386 设计的这套架构太流弊,它的后继者门也纷纷沿用并保持兼容。所以后来 Intel 将这套架构称之为 IA32 (32 Bit Intel Architecture)。又因为 IA32 家族最开始的 CPU 名称是 8086, 80286, 80386, 80486,所以,这套架构又被称作是 x86。
后记
本文写得太急,内容铺开太广,而作者水平有限。因此,文中难免有疏漏。此外,文章还应该补上许多释义说明的图,然而这几天我把 Mac 里的 TeX 系统折腾挂了,所以没有合适的绘图工具。
诸如此类,待后续修补。


