这篇文章的缘起有二:
- 很多人主张「应当在几乎所有情况下使用 C 风格的 I/O」(比如这里),而我很怀疑;
- 另一方面,在刷 POJ 的时候,使用
std::cin确实能 TLE 而改成std::scanf就 AC 了,因此想试试看std::cin能否加速。
中文网络里,已有码农场和 byvoid 菊苣的讨论。不过二者对于原理的解释,自我感觉都不够清晰;又本着自己动手做实验的坚持,决定写下这篇文章,探讨 C++ 的读入速度的问题,特别是读入文件速度的问题。
从稍微底层介绍起
std::cin 为什么慢?要解释这个问题,就得从稍微底层的角度说起。
以 Linux 为例。Linux 内核负责管理计算机硬件,对接硬件规格,向上提供系统调用(System Call)。内核之上的运行时库(Runtime Library)负责对接系统调用,向上提供操作系统应用编程接口(Operation System Application Programming Interface, OS API)。
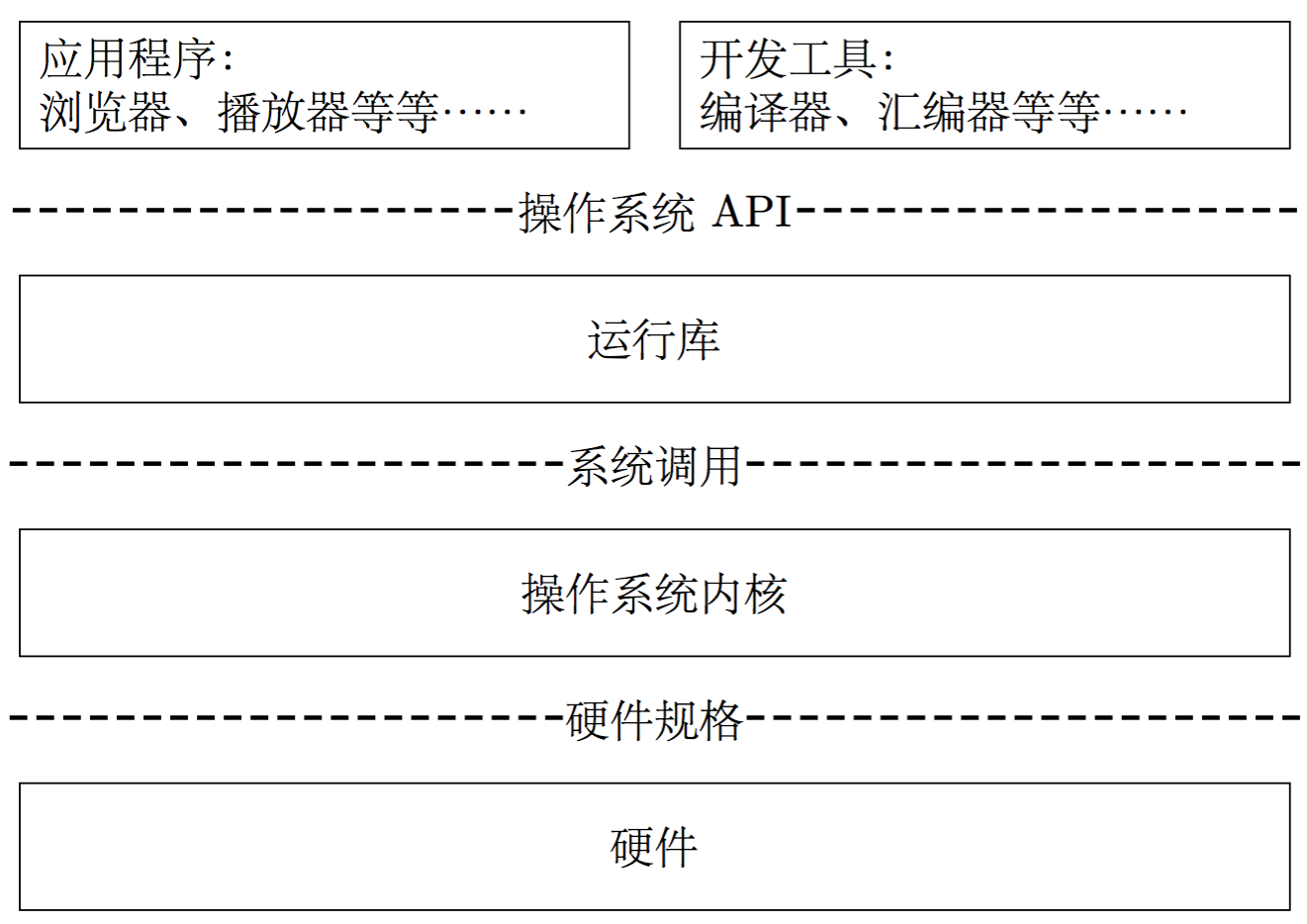
对于我们使用 C/C++ 编程来说,所作的几乎全部事情,都基于运行时库提供的 OS API(glibc 提供的 POSIX API);少数操作,可以通过 OS API 中提供的类函数直接操作系统调用(如 fork() 函数)。
因此,不难理解,不论是 std::cin 还是 std::scanf 都是对 OS API 的封装,而 OS API 又是对系统调用的封装。至于再往下,系统调用就直接通过内核操作硬件了。因此,可以粗略地估计,直接使用系统调用做 I/O 会比用 OS API 要快;而用 OS API 又会比封装 OS API 的语言库函数要慢。
我们这里讨论 std::cin 和 std::scanf,因此主要关系 I/O 中的 Input 部分。在 Linux 系统调用中,和文件读取相关的系统调用有两个类函数。
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);: 封装名为mmap2的系统调用(mmap自 Linux 2.4 起弃用);mmap将磁盘上的文件一一映射到实存空间,当进程调用相关内存的时候,通过缺页错误真正将文件内容拷贝到实存。ssize_t read(int fd, void *buf, size_t count);: 封装名为read的系统调用。这里ssize_t是__kernel_ssize_t的typedef;而__kernel_ssize_t在 32 位系统上是int的typedef,在 64 位系统上是long ing的typedef。read会从文件描述符(file description)fd中读入count个字节,存入buf缓存中。
由于 mmap 做的事情比 read 少(事实上它几乎只分配了内存空间并做了一个映射),所以 mmap 函数本身会比 read 函数快一些。
在标准库中,和输入相关函数的有以下一些。
size_t fread ( void * ptr, size_t size, size_t count, FILE * stream );: 从文件流中读取一块内容,存入ptr指向的内存。int scanf ( const char * format, ... );: 从标准输入中读入内容,并以格式化字符串将读入的内容存入相应的指针。std::istream: C++ 风格的输入流(包括std::cin等)。
std::cin 做了哪些额外的工作
通常为人诟病的是 std::cin 的速度。std::cin 是标准库里的东西。我们知道,标准库是要为千万人所用的东西,所以它对性能要求非常严格。按理说,标准库里的东西,只要正确使用,就不应该慢。那么现在,既然它慢,就有个原因。这个原因,又肯定是它做了额外的工作(相比 std::scanf)。那么 std::cin 做了哪些额外的工作呢?
事实上,为了「安全」,std::cin 主要做了两件额外的事情:
- 与
std::cout绑定,每次std::cin从缓冲区读入内容之前,确保已经执行过std::cout.flush(); - 与
stdio同步(synchronize),确保混搭使用 C 风格的 I/O 操作不会引发问题。
如果我们能手工确保不会出问题,那么就可以省略 std::cin 做的这些额外的工作。
std::ios::tie
首先我们解决「绑定」的问题。
绑定是通过 std::ios::tie 这个函数实现的。它作为 ios 类的成员函数,有两个重载。
ostream* tie() const: 返回当前绑定的输出流实例的指针。ostream* tie (ostream* tiestr): 返回当前绑定的输出流实例的指针,再将tiestr绑定到当前实例。
cplusplus 网站上提供了这样的示例:
1 | // redefine tied object |
默认情况下,std::cin 与 std::cout 绑定。因此第一次调用 std::cin.tie() 返回的是 std::cout 的指针。因此第一次输出将会打印到标准输出上。
之后,我们用 std::cin.tie (&ofs) 将一个文件输出流绑定在 std::cin 上,并将 std::cout 的指针存在 prevstr 中。这时候,第二次调用 std::cin.tie() 返回的是 ofs 的指针。因此第二次输出将会打印到 ofs 绑定的文件中(test.txt)。
因此,代码正确执行后,将会在控制台打印:
tie example:
This is inserted into cout
在文件 test.txt 中写入:
This is inserted into the file
为了解除 std::cin 与 std::cout 的绑定,我们可以这样做
1 | std::ostream *prevstr = std::cin.tie(); |
std::ios_base::sync_with_stdio
接下来我们解决同步的问题。
在所有输入输出流的基类(std::ios_base)中定义了 sync_with_stdio 函数。它的原型是:
1 | static bool sync_with_stdio( bool sync = true ) |
默认情况下,这个同步机制是打开的。于是,在 C++ 的流上做的任何操作,会被立即同步到相应的 C 的流中。因此,在代码里我们可以混搭 C 风格和 C++ 风格的流操作。
我们可以通过这样做,以解除 C++ 风格的输入输出流与 C 风格的输入输出流的绑定:
1 | std::ios_base::sync_with_stdio(false); |
实验
随机数生成
作为实验的预备,我们需要生成一组随机数,作为读入。这里计划生成的文件,样式为:
1 | a_1 b_1 |
其中,$a_1, \ldots, a_n$ 是随机整数,$b_1, \ldots, b_n$ 是随机浮点数。我们用 Python 来实现随机数的生成和输出。
1 | import random |
实验环境
- 编译器:gcc-4.7.2
- 操作系统:CentOS 5.4
- CPU 型号:Intel(R) Xeon(R) CPU E5645@2.4 GHz
- 主存大小:65979428 KiB
- 磁盘大小:388 GiB
实验代码
1 |
|
1 |
|
1 |
|
实验结果
这里用管道的方式,将输入数据传给编译好的可执行映像。
1 | cat foobar.txt | ./a.out |
这里将每一份数据重复输入可执行映像 5 次,然后去除最低和最高的执行时间,取中间三个做平均值,得到结果如下(单位:微秒)。
| 数据大小 | cin | cin -O2 | cin 加速 | cin 加速 -O2 | scanf | scanf -O2 |
|---|---|---|---|---|---|---|
| 1962 | 2179 | 1131 | 1020 | 754 | 773 | |
| 20099 | 20448 | 10496 | 9817 | 7187 | 7205 | |
| 139541 | 146781 | 75328 | 70302 | 52498 | 55002 | |
| 1401558 | 1382098 | 681064 | 651954 | 476777 | 481314 | |
| 13318033 | 13956841 | 6687289 | 6468692 | 4779453 | 4760468 |
从表中可以看出,std::scanf 在实验条件下速度始终最快,但与「加速之后的」std::cin 处于同一个数量级。而它们都比默认的 std::cin 要快出一个数量级。这个结论随着数据量的增长保持不变。
另外,使用编译器的 -O2 参数,打开编译器优化之后,std::cin 对优化不敏感,甚至在一些数据集上优化之后的速度反而变慢;加速之后的 std::cin 和 std::scanf 则对优化敏感,其中加速之后的 std::cin 对优化尤其敏感。
在这个实验中,std::scanf 的确在速度上有优势,似乎验证了「很多人」的主张。不过,tatanaideyo 做了类似的实验,结果表明:
std::scanf和加速之后的std::cin一定比std::cin快;std::scanf在读入浮点数时比加速之后的std::cin快;std::scanf在读入整形数值时比加速之后的std::cin慢。
总结
加速之后的 std::cin 并不一定比 std::scanf 慢;在大多数日常使用的情形下,其效率在渐进意义上与 std::scanf 相当。tatanaideyo 则表明,如果数据中包含大量的整形数值,则使用加速之后的 std::cin 会更有优势;反之若数据中包含大量的浮点数,则使用 std::scanf 更佳。
更多探讨可以参考:http://codeforces.com/blog/entry/5217
参考
- 《程序员的自我修养:链接、装载和库》
- http://www.tutorialspoint.com/unix_system_calls/read.htm
- http://man7.org/linux/man-pages/man2/read.2.html
- http://man7.org/linux/man-pages/man2/mmap.2.html
- http://www.cplusplus.com/reference/cstdio/fread/
- http://www.cplusplus.com/reference/cstdio/scanf/
- http://www.cplusplus.com/reference/ios/ios/tie/
- http://en.cppreference.com/w/cpp/io/ios_base/sync_with_stdio
- https://www.byvoid.com/blog/fast-readfile/
- http://www.hankcs.com/program/cpp/cin-tie-with-sync_with_stdio-acceleration-input-and-output.html
- https://heavywatal.github.io/cxx/speed.html
- http://tatanaideyo.hatenablog.com/entry/2014/10/24/214714
- http://codeforces.com/blog/entry/5217
- http://stackoverflow.com/questions/14052627/why-do-we-need-to-tie-cin-and-cout
- https://www.quora.com/What-is-use-of-the-statement-ios_base-sync_with_stdio-false-cin-tie-NULL-cout-tie-NULL-What-does-it-do
- http://www.cnblogs.com/huxiao-tee/p/4660352.html
- http://en.cppreference.com/w/cpp/chrono/duration


