前作简单介绍了计算机硬件的发展历史和当前计算机硬件的基本结构。我们知道,作为软件开发者,我们几乎只需要知道计算机硬件由 CPU、内存和 I/O 设备组成就可以了,其他细节不一定要详细地了解。
本文我们将简单介绍计算机的层次化结构和操作系统;而后讨论 Linux 中的进程与线程。
层次化的好处都有啥?
层次化的好处都有啥?谁说对了就给他!
——Liam Huang
说起层次化结构,计算机领域内最负盛名的可能是 TCP/IP 协议栈了。TCP/IP 的设计者,将整个网络通信协议,进行了层次化的设计:下面的层次为上层提供接口和功能,上面的层次负责调用接口完成新的工作。下层的服务对上层来说是透明的,只需要保证层次之间的接口不变,就能实现或者增强各种功能(比如 VPN)。
计算机科学领域的任何问题,都可以通过增加一个间接的中间层来解决。
Any problem in computer science could be solved by another layer of indirection.
这句话的出处已经不可考,但是它非常有名,并且道出了整个计算机系统软件体系结构的要点。
计算机系统软件的体系结构就遵循了层次化的体系结构,不仅如此,操作系统本身也遵循着这样的结构。计算机系统软件的体系结构大体如下图所示。
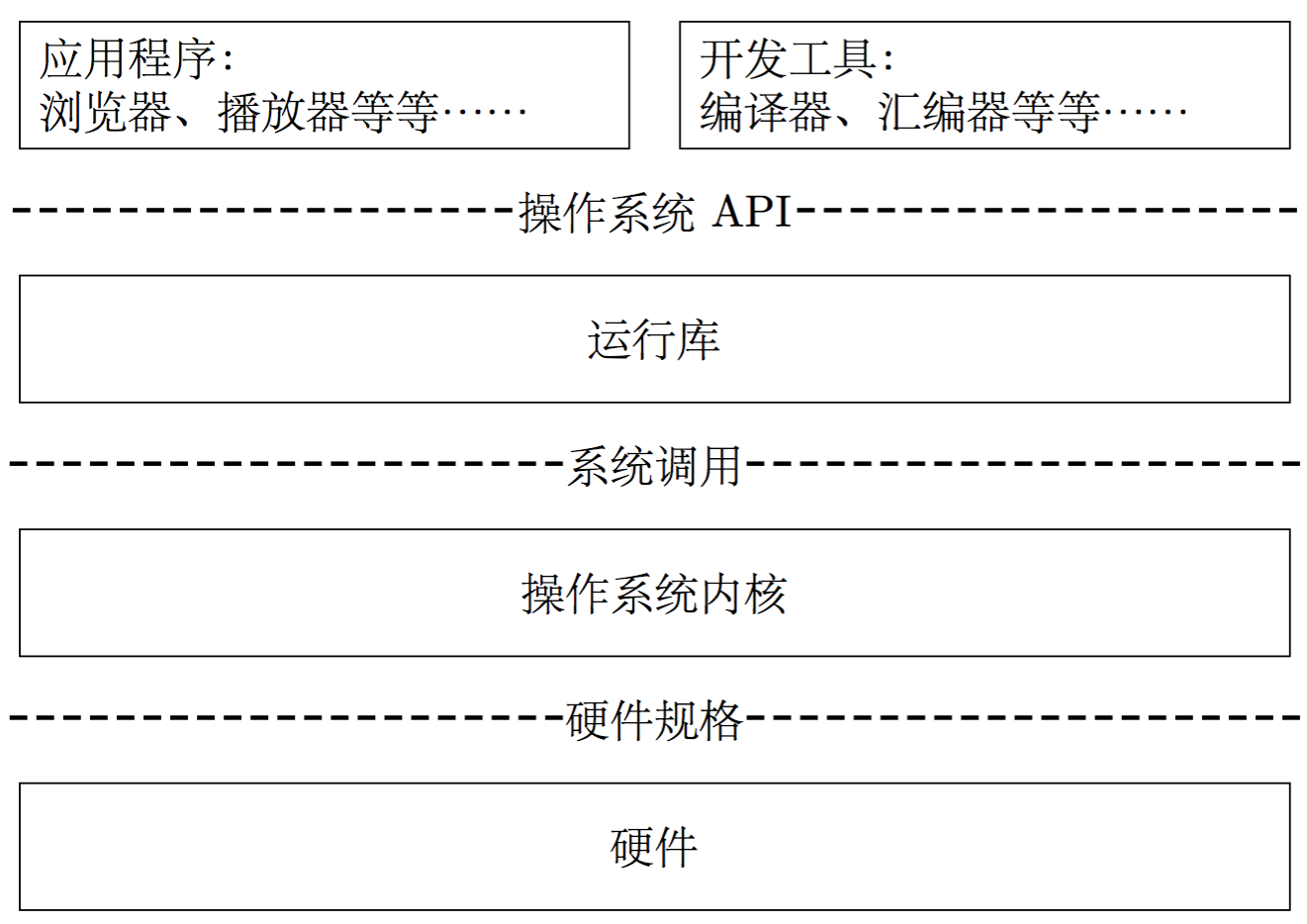
层次化结构之中,层次之间的通信规则被称为接口(interface)。在图中,方框框起来的是层次中的内容,虚线中间的就是接口。接口由下层定义,由上层调用;在这种框架下,上层通过调用下层提供的借口,使用下层提供的服务。正如上面所说,只要保证接口稳定不变,由于透明性,接口下方的每个层次都可以做修改甚至替换,这是兼容性的重要保障。
从图中,我们可以看出操作系统对上提供系统调用(system call)接口,对下根据硬件规格(Hardware Specification)实现对硬件的操作(具体来说,是由操作系统中的各种驱动来完成)。这就是为什么我们说,操作系统基本上就完成了两件事情:对上层提供抽象接口、对下层硬件资源进行管理。
操作系统都干啥?
操作系统对上层提供的系统调用,我们这里按下不表,主要看看操作系统在管理硬件资源方面做了哪些努力。
计算机硬件的能力是有限的。特别地,在计算机刚刚起步的阶段,计算机硬件通常是昂贵的。所以,为了充分发掘计算机的存储、运算能力,或者邪恶点说是榨干计算机的硬件资源,使得计算机在尽可能段的时间内处理更多的事情。
交给计算机的任务,大致可以分为两类:I/O 密集型任务和 CPU 密集型任务。顾名思义,CPU 密集型任务,在执行过程中,需要大量的 CPU 资源。对于这种任务,我们可以大胆地将 CPU 资源交给它来调用——反正总是要占用 CPU 资源的。大体上,涉及到磁盘 I/O、网络存取的任务,就都是 I/O 密集型任务;此类任务往往不需要太多 CPU 资源,对于 CPU 来说,大多数时间被空耗在等待 I/O 完成上了。当人们认识到交给计算机的任务可以分为这两类的时候,人们就开始考虑如何做 CPU 的任务调度。在任务调度上,人们经历了多道程序、分时系统与多任务系统等阶段。
在多任务系统中,操作系统接管了所有硬件资源并持有对硬件控制的最高权限。在操作系统中执行的程序,都以进程的方式运行在更低的权限中。所有的硬件资源,由操作系统根据进程的优先级以及进程的运行状况进行统一的调配。
进程和线程
这里提到,「在操作系统中执行的程序,都以进程的方式运行在更低的权限中」。事实上,操作系统是以进程为单位去分配空间和执行的。但是,进程和程序有什么不同呢?我们说
- 程序是一组指令的集合,它静态存储于诸如磁盘之类的存储器里;
- 当一个程序被操作系统执行时,它就会被载入内存空间,并在逻辑上产生一个独立的实例,这就是进程。
这就好像是说,程序是一道菜谱,其中的指令,就是指挥你开火加盐的步骤;进程则是烹饪的过程,操作系统按照指令一丝不苟地烹饪,得到的结果就是我们的菜肴。
随着 CPU 频率增长逐渐停滞,CPU 开始向多核的方向发展。为了让多个 CPU 核心同时为我们工作,并行地执行任务,就需要涉及线程的概念。线程的英文是 Thread,有时也称为轻量级进程 (Lightweight Process),它是操作系统进行任务调度的最小单元。线程存活于进程之中;同一个进程中的线程,共享一个虚拟内存空间,以及其中的资源;线程之间各自持有自己的线程 ID、当前指令的指针(PC)、寄存器集合以及栈。
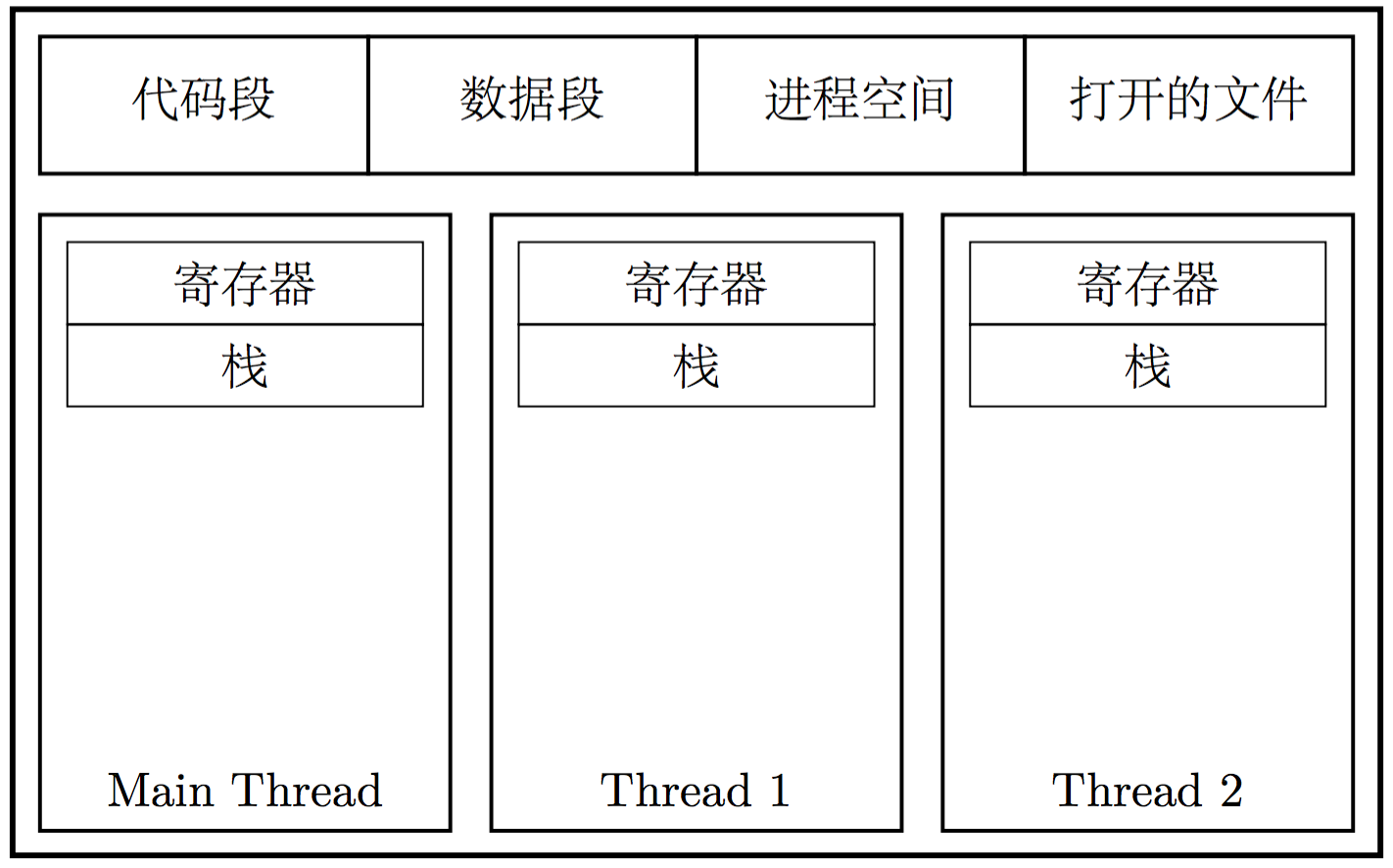
通常来说,使用多线程会带来一下一些优势:
- 将等待 I/O 操作的时间,调度到其他线程执行,提高 CPU 利用率;
- 将计算密集型的操作留给工作线程,预留线程保持与用户的交互;
- 在多 CPU/多核计算机下,有效吃干计算能力;
- 相比多进程的程序,更有效地进行数据共享(在同一个进程空间)。
Linux 中的进程与线程
在 Windows 中,有明确的 API:CreateProcess 和 CreateThread 来创建进程和线程。但是,在 Linux 中,不管是进程还是线程,都以任务(Task)视之。也就是说,在 Linux 中,实际上并不存在概念上严格的线程和进程的区别。不过,这并不是说在 Linux 里就无法实现多线程了。由于 Linux 支持在进程之间共享物理内存空间,因而在实际意义上,支持了多线程。
为了说明 Linux 中进程与线程的概念,这里要引入三个 Linux 中的运行时库函数:fork(), exec 和 clone()。
fork() 函数
fork() 是 Linux 中的一个运行时库函数。它会调用 syscall_clone(),也就是系统调用 clone,复制一个与当前进程一模一样的进程,并且新进程与原进程以写时复制(Copy on Write)的方式共享同一份内存空间。
每当 fork() 函数被调用时,都会产生两次函数返回:
- 在父进程中返回一次,返回值是子进程的 PID;
- 在子进程中返回一次,返回值是 0。
这使得我们可以分别控制父进程和子进程的执行过程。
1 |
|
它的执行结果是
1 | I'm the father, and I have 42 apple(s). |
exec 函数
事实上,exec 是一系列函数,它至少包括:
1 | int execl(const char *path, const char *arg, ...); |
这些函数内部都会调用库函数 int execve(const char *filename, char *const argv[],char *const envp[]);,该函数会将当前进程空间清空,而后根据传入的参数装载指定的可执行文件(二进制或者脚本)来执行。
1 |
|
1 |
|
执行结果
1 | I'm the father, and I have 42 apple(s). |
这里我们可以看出,在父进程中,「我有 42 个苹果」顺利被执行;同时在子进程中,我们使用了 execl 函数调用了外部可执行脚本,它成功地打印了预期的内容。值得注意的是,printf("Something that will never be printed.\n"); 并没有执行。这是因为,在子进程执行到 execl 之后,进程空间中的内容就被清空了,execl 之后的指令永远不会有机会执行。
可见:使用 fork() 函数可以创建子进程;使用 fork() 函数以及 exec 函数则可以在子进程里执行新的任务。
clone() 函数
这里介绍的 clone() 是一个库函数;与之同名的,还有系统调用 clone——我们在介绍 fork() 函数的时候已经见过它了。
clone() 函数的原型是
1 | int clone(int (fn)(void ), void *child_stack, int flags, void *arg); |
clone() 函数会创建一个子进程,从指定位置开始执行,并有选择地继承父进程的资源。具体而言
fn是一个函数指针,子进程将会从这里开始执行;child_stack是指向一片内存空间的指针,它会被子进程用作栈内存,并且需要在父进程里分配好空间;flags是标志位,它会改变clone函数创建的子进程对父进程资源继承之行为;arg是一个可变长的参数,这些参数会被传递给fn,并且应当以显式的NULL指针作为结尾;- 当
fn函数在新的进程中执行完毕(或者显式地调用exit()函数退出时),子进程被销毁。
这里可用的标志位有很多,详细地可以去查阅 clone() 函数的手册。我们重点关注的是 CLONE_VM 这个标志位。当它被传给 clone() 函数的时候,新进程和老进程共享同一内存空间:新进程和老进程对内存的写入操作,在另一个进程里是可见的;并且使用 mmap() 和 munmap() 操作也是互通的。
我们来看一个示例。
1 |
|
它的输出是
1 | In the calling thread: getpid[142059], getppid[119147]. |
这个例子说明了几个问题
- 传给
clone()函数的新进程的栈地址,是栈顶的地址;这是因为栈总是从上向下扩张使用的。 - 执行
clone()之后,原进程会继续执行(而不会阻塞);因此我们需要等待一些时间再释放分配给新进程作为栈使用的内存空间,否则会引发 core dumped。 - 在新进程里对
index变量的修改,在原进程里是可见的,这说明新进程实际上是一个线程。 - 尽管实际上它是一个线程,但是仍然占据了一个进程号(PID),并且以原进程为父进程。
你也可以试着在执行 clone() 函数的时候,将传入的标记设置为 CLONE_SIGHAND|CLONE_VM|CLONE_THREAD,再看看结果会怎样。
这里,我们介绍了三个与多进程/多线程相关的库函数,并以 clone() 函数真正在进程中创建了一个线程。但是,在 Linux 里进行多线程的编程,我们通常会使用 pthread 库来创建新的线程。这里只给出最简单的例子,不做深入探讨。
1 |
|
执行结果
1 | In the calling thread: getpid[10000], getppid[119147]. |
线程安全浅说
首先,我们回顾一下线程的特点:
- 每个线程有自己独立的栈;
- 同时多个线程共享进程空间中的数据。
竞争
如果每个线程对共享部分数据都是只读的,那么大概不会出现什么问题。但是,如果同时有多个线程尝试对同一份数据进行写入操作,那么最终的结果可能会是不可预期的。考虑这一经典的例子:
- 共享数据
int i = 0;; - 线程 1 试图执行
++i; - 线程 2 试图执行
--i。
首先考虑 ++i 背后的意义(--i 类似)。在大多数体系结构上,++i 在编译出的汇编代码中,会被翻译为
1 | X <- i # 将 i 的值读入某个寄存器,比如 X 或者 Y |
由于这一句代码会被翻译成多条指令,那么必然存在这样的情况:线程 1 在执行三条指令的过程中被中断,系统调度线程 2 继续执行。这样,在两边线程执行完毕之后,变量 i 的值可能是 0, 1, -1;而具体取值多少是不可预期的。这种因为多个线程竞争对同一变量进行操作导致不可预期后果的过程,称为线程不安全。
原子性
回顾刚才的分析,线程不安全的根本原因,是线程中多条指令连续执行的过程可能会被系统调度中断,而现场恢复之后共享变量的值可能已经被修改。因此,如果我们能保证指令的执行不被打断,那么自然就能保证线程安全了。这种特性被称作原子性。
显然,单条指令是不可打断的。那么对应单条指令的代码,都是具有原子性的。例如 i386 架构中,有一个 inc 指令,可以直接增加内存某个区域的值。这样一来,自增操作就是原子的了。
由单条指令提供的原子性,显然有非常大的局限性——这是因为单条指令能够达成的效果总是有限的。在实际生产中,我们会需要保证连续多条指令的原子性。这就需要引入同步和锁的概念。
同步与锁
在这里,同步是一种规则,而锁则是实现这种规则的具体方法。
所谓同步,指的是多线程程序里,多个线程不得同时对某一共享变量进行访问。锁是实现同步的一种具体方案——准确地说,这是一种非常强的方案。锁有多种形式,最符合直觉的锁是所谓的互斥量(Mutex)。具体来说,线程在访问某个共享变量的时候,必须先获取锁;如果获取不到锁,那么就必须等待(或者进行其他操作,总之不许访问这个变量);在结束对这个变量的访问之后,持有锁的线程应当释放。
值得一提的是,所作为一种同步手段,是非常强的。但是,这种强,仅限于逻辑层面。在实际情况中,编译器优化、CPU 动态调度,都有可能打破锁对于同步的保护。这时候,这些优化就变成了过度优化。
过度优化对线程安全的破坏
这一小节我们会举 2 个例子,说明在某些情况下锁也是不靠谱的。
编译器优化
1 | int x = 0; |
对于共享的变量 x,我们在线程 1 和线程 2 中并发地尝试访问它。为了保证线程安全,我们在对它的访问前后加上了锁。在逻辑上,这已经做到了线程安全,于是在执行完毕之后,x 的值应当必然是 2。但是,编译器优化可能会破坏逻辑上的线程安全:如果线程 1 在这之后会多次使用变量 x,那么编译器可能会将 x 自增后的值存放在寄存器中,暂不写回。于是,在线程 2 中尝试自增 x 的时候,获取到的 x 的值,可能是尚未从线程 1 的寄存器中更新值的 x。整个流程如下:
- 线程 1:获取锁
- 线程 1:从
x中读取数据,写入寄存器X - 线程 1:
X++ - 线程 1:释放锁
- 线程 2:获取锁
- 线程 2:从
x中读取数据,写入寄存器Y - 线程 2:
Y++ - 线程 2:从寄存器
Y中读取数据,写入x - 线程 2:释放锁
- 线程 1:(很久之后)从寄存器
X中读取数据,写入x
显而易见,最终 x 的值,取决于寄存器中 X 的值;而在这个例子中,它是 1。
对于这种情况,我们可以用 C 语言关键字 volatile。这个关键字能在两种情况下阻止编译器优化:
- 为了提高速度,将一个变量缓存到寄存器而不写回;
- 调整操作该变量的指令的顺序。
因此,在这个例子里,我们只需要使用 volatile int x = 0,就能保证 x 变量总是能得到即时的更新了。
CPU 动态调度
程序在执行的过程中,出于效率的考量,两个(在当前线程中)没有依赖的指令可能会调换顺序执行。对于 CPU 来说,这已经是几十年的老技术了。我们来看这段 C++ 代码
1 | volatile T* pInst = nullptr; |
在单例模式中,这是一段典型的 double-check 的代码。双层的 if 各有作用:
- 外层
if确保仅在pInst是空指针的情况下才去获取锁并尝试构造对象; - 内侧
if则是为了防止这样一种可能,避免重复操作和内存泄露:在外层if检测是,pInst尚为空,但是,待lock()执行完毕后,别的线程已经为pInst赋值。
这段代码,乍一看是没有问题的;但仍需小心揣摩。我们看 pInst = new T; 这一行代码,它基本完成了三件事情
- 为
T类型的对象分配内存; - 在这片内存上执行
T的构造函数; - 将这片内存的起始地址赋值给
pInst。
由于构造函数的执行和指针的赋值是互不依赖的,所以 CPU 可能会交换这两个步骤的顺序。因此,在线程执行的过程中,可能存在这样一种情况:nullptr != pInst,但是它指向的对象尚未构造成功。于是,如果在这一时刻,当前线程被中断,并且其它线程调用 GetInstance 函数,那么函数在外层 if 执行之后,会直接返回 pInst 的值。而此时 pInst 实际上指向的是一片尚未初始化的内存。如果线程代码对 pInst 进行访问,那么程序很有可能就会崩溃。
为了解决这类 CPU 动态调度导致的问题,我们需要有在某些情况下阻止指令换序执行的能力。然而遗憾的是,由于动态调度是 CPU 的功能,所以在高级语言的层次,我们没有通用的解决办法——只能依赖具体的 CPU 架构,对代码进行调整。对于 i386 架构的 CPU 来说,它提供了一条指令 mfence(memory fence 的缩写),可以阻止这种换序执行。
1 |
|
在这里,我们用 barrier() 保证了在 pInst 被赋值之前,相关内存区域已经正确地初始化了。
可见,线程安全是个烫手山芋。为了写出线程安全的程序,程序员们都需要好好学习一个。


