C++ 几乎是这个世界上最为复杂的编程语言(Programming Language)。C++ 的标准中有无数的细节,然而让人迷失在细节中,并不是 C++ 设计者/标准化委员会的本意。实际上,写好 C++ 程序,也不需要了解 C++ 的每一个细节;只需要理解语言背后的基本原理和技术就可以了。
C++ 语言之父(Bjarne Stroustrup)在 2012 年撰写过一篇 paper,其名为 Foundations of C++。在这篇 paper 中,Bjarne 通过一些例子,介绍了 C++ 背后的这些基本原理和技术。本文即脱胎于 Bjarne 的这篇 paper。
C++ 的理想化目标
所谓「术业有专攻」,每个工具都有其适用范围;在适用范围内,每个工具又都有特别擅长的部分。作为工具的使用者,我们自然会期待在每一个范围,使用擅长解决这部分问题的工具。因此,如果把编程语言当做是一种工具,那么学习编程语言就应该了解其设计目的和擅长范围。
特别一提,在有此理解的基础上,就会明白,市面上诸如「PHP 是最好的语言」、「Emacs 与 Vim 之争」是多么的无聊了。
C++ 在设计之初,就着眼于特定的编程任务:在资源有限的情况下,为关键性的基础服务提供轻量级的抽象支持。我们可以认为,这就是 C++ 特别擅长的部分。为此,C++ 在语言特性和标准化的过程中,在两个方面着重下了功夫
- 简单直接地对硬件做映射(继承了很多来自 C 语言的特性);
- 零开销地抽象机制(zero-overhead abstraction mechanism)。
在更高的层次上,这两方面的功夫,为 C++ 提供了既类型(type)丰富又类型安全的编程环境。
自然,并不是每个编程任务都落在 C++ 擅长的领域。实际上每个语言都有擅长和不擅长的领域。在这些领域,你就不能指望 C++ 程序员一定要遵循这些理想化的基本原理和技术——他们可以使用 C 风格的 C++ 去完成他们的目标。
内存与对象(Object)
C++ 将内存视作一长串的字节(sequence of Bytes)。在 C++ 代码和硬件之间,C++ 没有做额外的抽象、虚拟或者其他的数学模型。这也就是说,指针、引用、数组这些概念,会直接反应在硬件上以及寻址上。
具体来说,C++ 将基本类型(char, int, double 等)直接映射到内存中的实体——比如字节(Byte)、字(Word)。有类型的对象会在内存中占据一块空间(a sequence of Bytes);而后,这些对象的值就存储在这块空间当中。与之对应,一系列的对象,就会在内存里占据一系列的空间——这就组成了数组。对于数组中的对象,我们通常会使用指针去访问——数组的头部指针,以及数组的尾后指针限定了数组有效区域的范围(类似左闭右开的区间)。
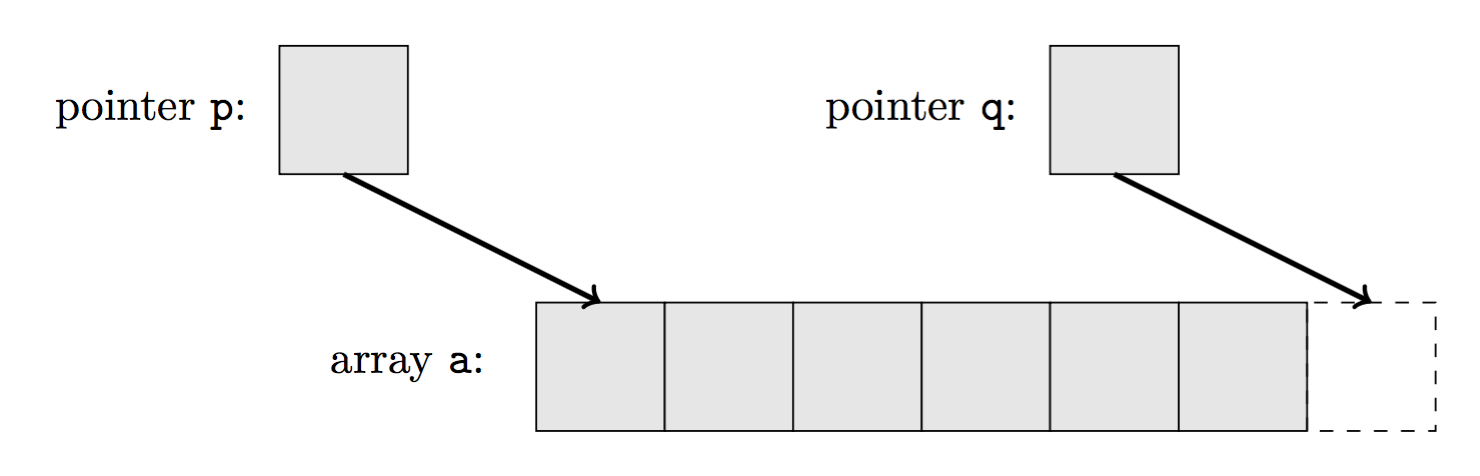
对于用户定义的类型来说(即 C++ 中的类),其在内存中的形式,仅只是类型内成员的加和而已。在提供抽象(类)的过程中,C++ 并没有带来额外的开销。此处以 Point 类为例,进行说明。
1 | class Point { |
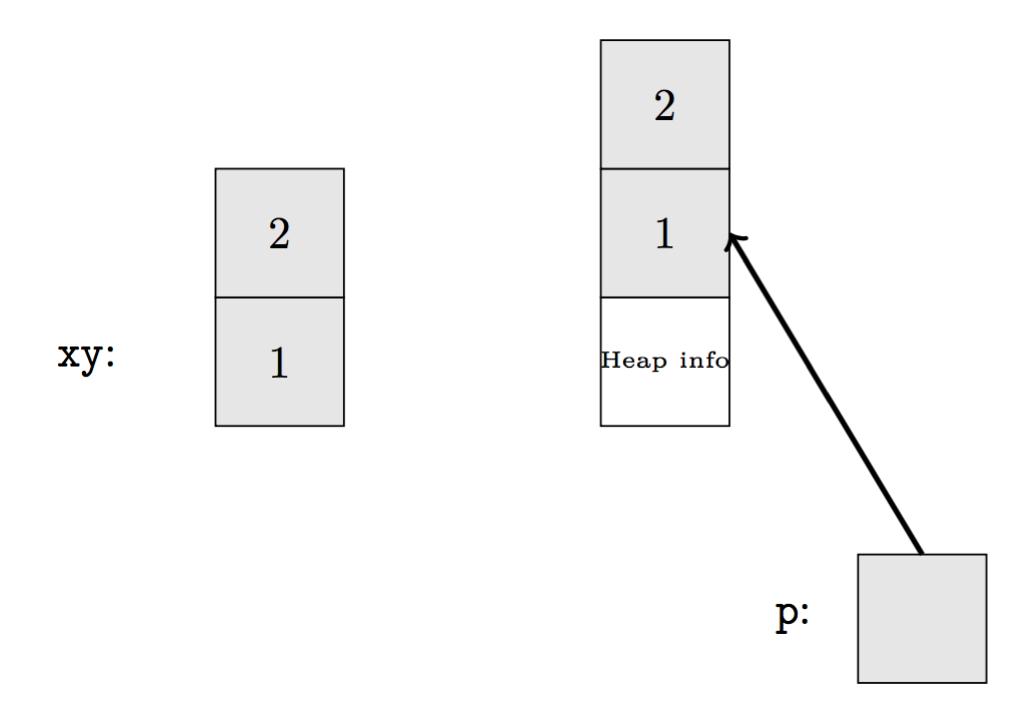
注意,这里我们使用了 C++11 的列表初始化(构造函数用花括号传参)。
这里,我们定义了 Point 类,其中有两个 int 类型的变量。于是,Point 类型的变量仅只是两个 int 的「组合」而已。在(栈)内存中,Point xy 占据了两倍 int 所需的内存空间;在(堆)内存中,指针 p 指向的对象,因为保存在堆中,所以有堆信息的额外开销(不可避免的)。
在继承机制里,C++ 也没有额外开销。
1 | class Base { |
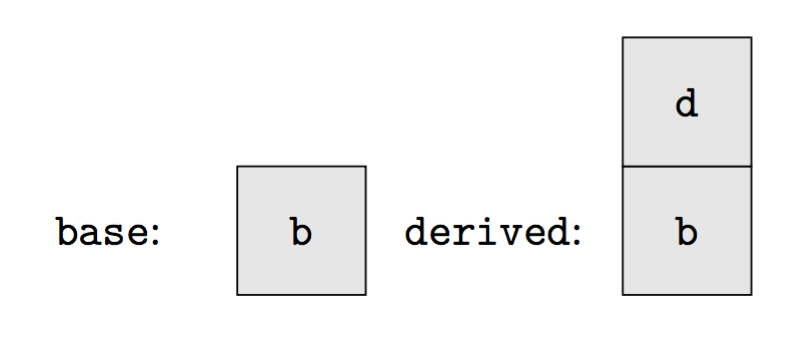
C++ 的类机制,仅只在引入虚函数时,才会带来一些开销(需要维护虚函数表)。这部分开销,是为了实现运行时多态(run-time polymorphism)所必须的,是不可避免的。因而,也没有额外的开销。
1 | class Shape { |
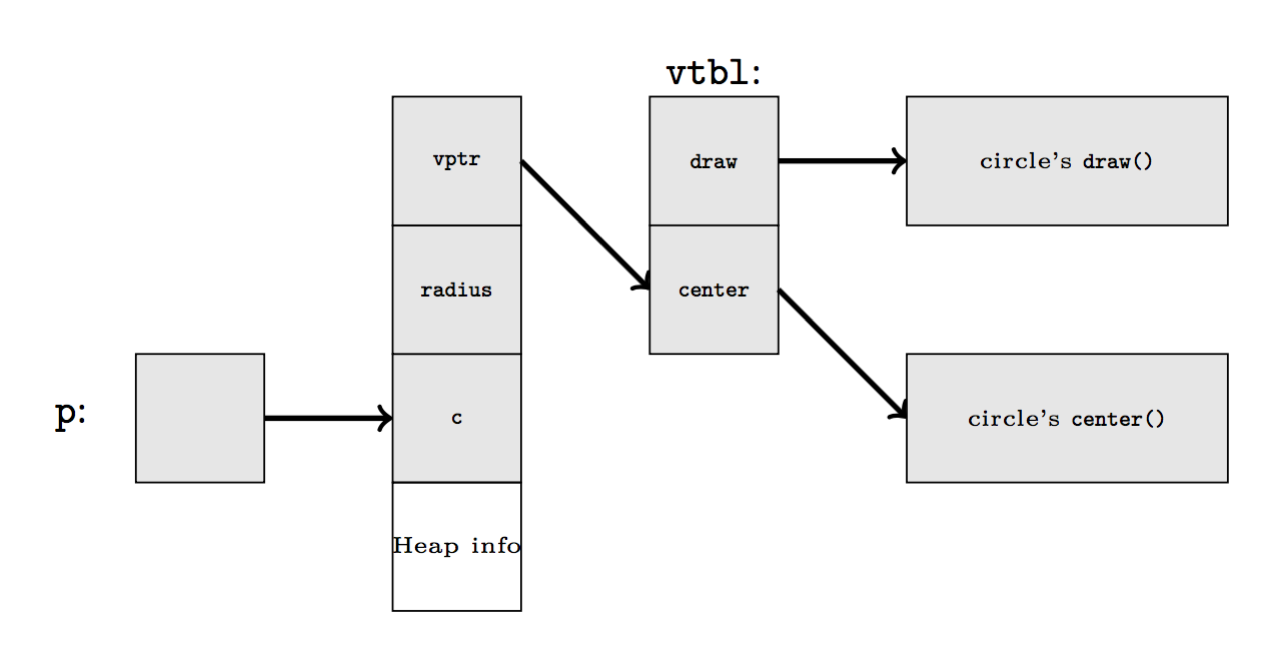
注:此图有误。虚表指针应该位于起始地址上。
至此,我们只是在「理论上」分析为什么 C++ 避免了各种额外的开销,却不知道哪些开销可称得上是额外的。当我们把自定义类型和数组结合起来时,与其它语言对比,就能看到差别了。(以某纯面向对象语言为例)。
1 | Point points[] = {{1, 2}, {3, 4}}; |
复用之前 Point 的定义,在 C++ 当中,points 这个数组在内存中的存储大致如下图。
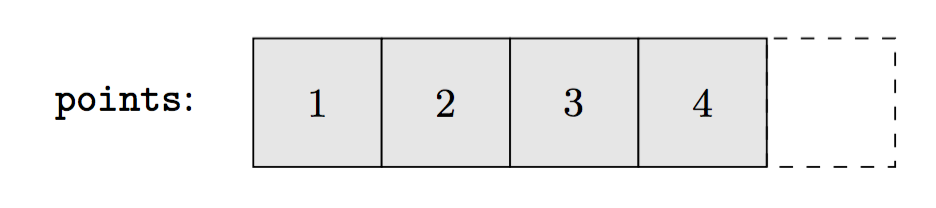
在某语言中,用户定义的类型,其对象实际保存在 heap 上,而通过 reference 访问。如此一来,同样的数组,在内存中的存储就与 C++ 的情形不太一样了。
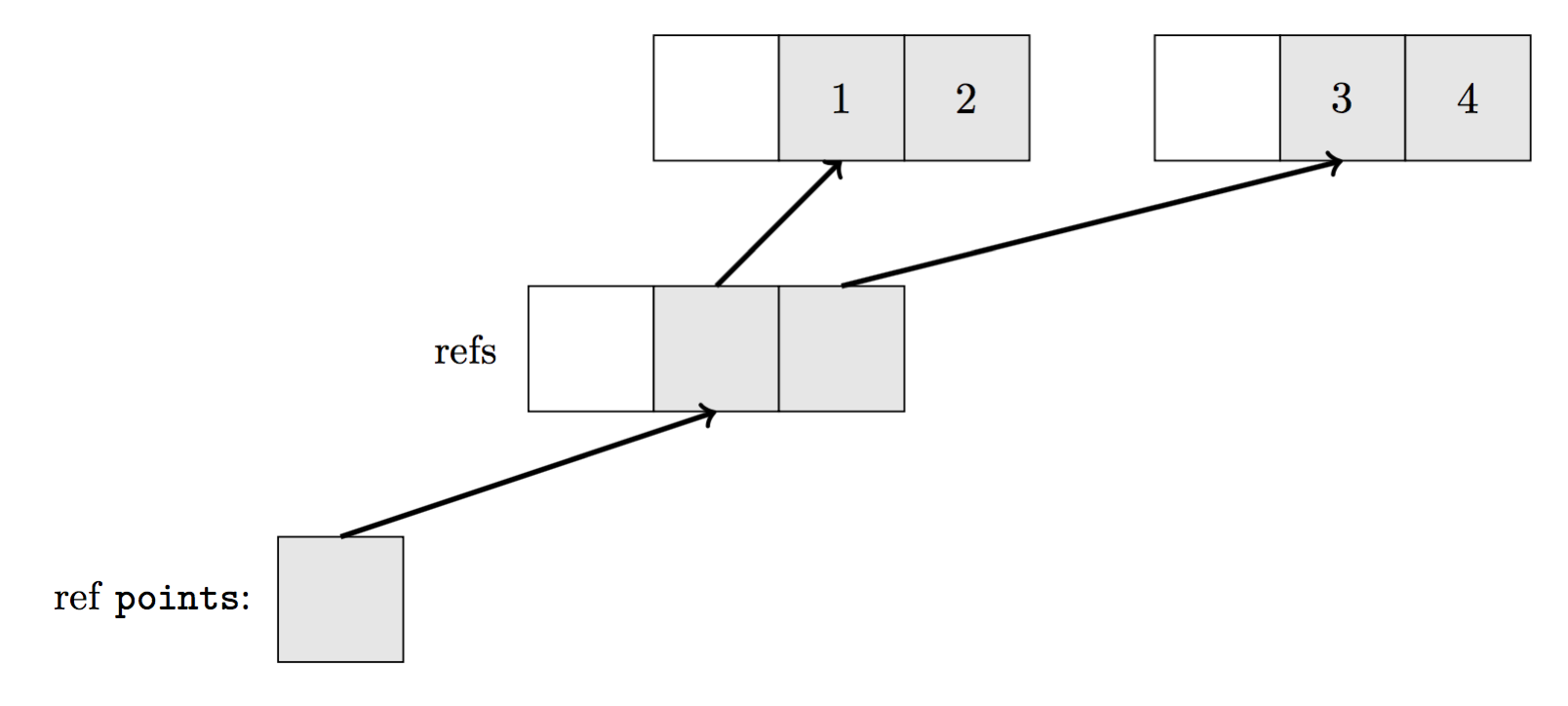
不难发现,在 C++ 中,统共只需 4 个 int 类型变量;但是在某语言中,同样的数组,至少需要 10 个 int 类型变量占据的内存。由于增加了实际内存使用量,所以在实际运行中,可能会降低 CPU cache 命中率,最终导致运行效率降低。
总而言之,C++ 在设计之时就在尝试避免各种额外的开销。而并不是每个语言都有这样的设计。
编译时运算
顾名思义,编译时运算指的是发生在编译期间(包括编译器优化)的运算。在编译时运算有以下一些好处
- 高效:以编译时的运算代替运行时的运算,提高运行时效率;
- 类型安全:在编译时就能检查表达式各部分的类型,保证类型安全;
- 简化并发:编译时运算得到常数,在常数上不会有数据竞争,因而能简化并发。
在 C++ 中,C++11 引入了 constexpr 这个关键字。编码时使用它,就能实现编译时运算了。下面的代码在编译时计算了北京与上海之间的距离。
1 | class City { |
容器
容器是 C++ STL 中的一大利器,可以用来存储大量内容。vector 是其中的代表。此处我们通过事先简易版本的 Vector 来说明 C++ 的容器。
1 | template<typename T> |
C++11 提供的 range-for 可以对所有提供 begin() 和 end() 的容器做循环迭代;这是容器的一个重要属性。比如说
1 | Vector<std::string> demo({"Hello", "world"}); |
在 Vector 类的声明中,值得注意的是使用了 public 和 private 关键字,将 Vector 的声明分为了外部接口和内部实现两个部分。在 Vector 的外部接口中,还包括了类的构造函数和析构函数——管理类实例的资源。
1 | // 初始化一个长度为 n 的 vector,内部元素默认初始化 |
我们首先在初始化列表中,将成员变量 sz 和 elem 初始化。其中 elem 指向了一块类型为 T 而长度为 sz 的 heap 内存空间。随后,我们在函数体中,用 std::uninitialized_fill 给 elem 上的空间,都以类型 T 的默认构造函数初始化。
注意,这里的
allocate<T>()只是一个「表意」的作用,是标准的 allocator 的简化版本。
1 | // 列表初始化 |
在列表初始化版本的构造函数里,构造函数接受一个用于初始化的列表。它将列表的长度初始化给 sz,而后同样地为 Vector 分配 heap 内存空间。在函数体里,使用 std::uninitialized_copy 将列表中的内容拷贝到 elem 指向的内存当中去。
1 | // 析构函数,拆掉为所有元素分配的内存 |
在析构函数中,我们逐一析构了 elem 当中的所有元素,而后释放了 elem 这块内存空间。
同样地,
deallocate<T>()也只是表意用。
这个简单的 Vector 提供了对内存的高级抽象。它将存储从一连串的字节(sequence of Bytes)抽象成了对象的容器(containers of objects)。并且,在这个抽象过程中,除了必要的错误检查、内存管理和初始化工作之外,并没有额外的开销;因而是非常轻量级的。
这个示例了 C++ 的一些基础技术和特性。最浅显地,C++ 语言本身并没有定义容器和内存管理,这些工作都需要用户自己定义(当然,大多数情况标准库已经为我们准备好了);C++ 语言本身,只是实现了对固定大小数组的支持。标准库中的 vector, map, set, list 等容器是学习 C++ 基础技术和特性非常好的示例。它们用到了以下一些技术:
- 接口与实现分离;
- 使用构造函数和析构函数管理资源(包括内存资源);
- 使用模板,以便容器支持多种类型的实例;
- 使用左闭右开的区间(
[begin():end()))构建for循环及相关算法; - 使用标准库提供的设施(一些有用的工具库和工具函数),简化实现。
拷贝和移动
这部分内容,可以参考前作:谈谈 C++ 中的右值引用以及C++ 中类的拷贝控制。
这一节我们继续讨论容器相关的技术。
上一节中,我们初步实现了一个简单的 Vector。但是这个 Vector 还非常的不完整。考虑下面这个例子
1 | Point* p1 = new Point{1, 2}; |
这里,我们首先列表初始化了 points。这是一个 Vector,内里的元素是 Point* 类型的对象。而后,我们尝试将 points 拷贝赋值给 points_holder。由于我们没有为 Vector 类定义「拷贝赋值」这个动作,所以编译器会为我们默认「合成」一个拷贝赋值运算符。
编译器默认合成的拷贝赋值运算符,只是简单地拷贝了类的成员变量,而不考虑成员变量的含义。具体到我们的例子中,默认合成的拷贝赋值运算符,会让 points_holder 的 sz 和 elem 分别具有和 points 中相应成员相同的值。对于 sz 来说,二者的值相同没有什么问题。但是对于 elem 来说,二者具有相同的值,意味着两个 Vector 共享了同一片内存空间。这样一来,就会出问题。比如说
- 向
points中增加了一个新的元素,那么elem这片空间上的元素数目变成了 3,但是points_holder.size()依然会返回 2; - 析构
points的时候,会导致points_holder也不可用(访问points_holder内的元素会引发 segfault)。
因此,我们需要对拷贝的行为作出具体的定义。
1 | // 拷贝构造函数 |
这里我们分别定义了 Vector 的拷贝构造函数以及拷贝赋值运算符;其中,在拷贝赋值运算符中,我们借助了拷贝构造函数。这样一来,不论是通过构造函数进行拷贝,还是通过赋值运算符进行拷贝,我们都有了完整的定义。
值得注意的是,在拷贝构造函数以及拷贝赋值运算符中,我们都使用了诸如 orig.sz, tmp.elem 这样的用法。但是,不论是 sz 还是 elem,都是 Vector 中定义的私有成员。那么为什么我们可以通过这样的方式访问呢?需要注意的是,C++ 中的类成员访问控制,是建立在「类」这个层面的,而不是「对象」这个层面的。这也就是说,你可以在一个实例中访问同一个类的不同实例当中的私有变量。
至此,我们解决了「拷贝」的问题,可以接着去解决「移动」的问题了。对于拷贝,我们比较容易理解。对于「移动」,可能很多人就无法理解它的必要性了。这里从两个角度去解说这个问题。
- 对于某些容器,我们希望禁止拷贝。比如著名的智能指针
unique_ptr。因为限定了「只有当前一个只能指针指向某个资源」,所以必须禁止对unique_ptr的拷贝。否则的话,就可能存在多个unique_ptr指向同一个资源。而这就与unique_ptr的定义相违背了。但是,我们又不可避免地会需要在不同的变量名之间传递智能指针(比如作为参数传递,或者放入容器时有容器的拷贝)。所以,在这种情况下,我们会需要「移动」的操作。 - 对于某些容器对象,有时会有这样的操作:将整个对象拷贝给另一个对象,而后当前对象就要被销毁了。如果被拷贝的容器非常大,整个过程就非常耗时了。这种情况下,如果能实现「移动」操作,无意就能省去很多不必要的拷贝;提高效率。
到这里,我们能明确地说:移动操作是有必要去实现的。但是,在具体去实现移动构造函数和移动赋值运算符之前,我们还需要做一些深入的思考:被移动的对象有哪些特征。为此,我们不妨回想一下日常生活中,移动一个物体会发生什么。
- 最最显而易见地,将一个物体移动之后,物体出现在新的位置,而从旧的位置消失了。
- 在某些情况下,比如当一个物体放置很久之后,我们移动它,会在旧的位置留下一堆灰尘。
作为程序员,我们要经常从现象中抽象出统一的规律。这两个现象告诉我们几件事情:
- 当一个物体被移走之后,它应该完好无损地出现在新的地方;
- 当一个物体被一走之后,原来所处的位置,可能出现各种情况——可能只是空出了位置,也可能留下一堆垃圾。
抽象到程序设计中,就应该是:当一个对象被移动走之后,我们不应该这个对象的状态做任何假设——可能还是保持原样,也可能留下了一堆无法理解的垃圾信息。简而言之,当一个对象被移动走之后,这个对象就应该被废弃,不应该使用了。
在 C 和 C++ 中,这种「马上就要被废弃」的对象有一个名字,叫做「右值」。因此,移动构造函数和移动复制运算符的参数,应该是一个右值。
1 | template<typename T> |
至此,我们已经实现了 Vector 类的移动和拷贝构造函数及赋值运算符,应当更新一下 Vector 类的声明。
1 | template<typename T> |
不难发现,拷贝构造函数及赋值运算符接受相同类型的左值引用,而移动版本的构造函数及赋值运算符接受相同类型的右值引用。
对于拷贝和移动控制,简单而粗暴的论断是:在析构函数、拷贝和移动构造和赋值运算符中,只要有一个需要手工实现(而不能依赖编译器自动合成的版本),那么就必须实现另外四个。
RAII (Resource Acquisition Is Initialization)
至此,我们(看似)已经可以结束有关容器的讨论了。但是,在上述几个章节里贯穿始终的问题还需要做更进一步的讨论——资源的管理。
要讨论资源的管理,首先要明白,站在程序设计语言的角度,到底什么是资源?Bjarne 对资源作出了这样的定义:凡是程序从系统的其他部分获取,并且在使用完之后需要(显式地或者隐式地)归还的东西,都是资源。按照这个定义,内存显然是一种资源。同样地,文件、套接字、锁、线程,都可以是一种资源。
同时,Bjarne 也给出了「资源泄露」的定义:凡是使用完应当归还而没有归还的资源,就是被泄露的资源;而这个现象叫做「资源泄漏」。资源的获取与释放,这两件事情本身并不值得长篇大论。但是防不胜防的资源泄漏,则需要好好讨论。
稍有经验的程序员,就不会对「资源泄漏」感到陌生。Java 程序员可能会感到轻松,因为 Java 有自带的垃圾回收机制,能避免大多数的内存泄露问题。然而,垃圾回收并不是解决资源泄漏的银弹;因为,垃圾回收只解决了「内存泄漏」的问题,但是还有其他形式的资源。此外,资源泄漏之所以令人感到棘手,还有一个原因就是它的隐蔽性:
- 有一些资源,看起来就不是个资源。比如在 C 程序中打开一个文件,其实获得的是一个指针
FILE*。调用fclose()本身就显得比较怪异(关闭一个指针,这是什么鬼)。 - 有一些资源,获取和释放的方式有很多种。于是,经常性地,程序员可能无法完美地给他们对应上。
- 及时程序员非常小心,在使用完了资源都主动释放,也有可能在出发释放动作之前,遇到函数返回、异常处理等问题,而跳过释放动作。
所谓解决问题的最好方法,是让问题发生的前提消失。
对此可以举一个生动的例子。
我们知道,在飞机、高铁等运输工具上,卫生间都采用一种名为「真空集便器」的装置来收集排泄、排遗产生的垃圾。身形瘦的人大约不会有这样的困惑,但是,如果一个大胖子一屁股坐到坐便器上,然后上完厕所,按下身前的冲洗按钮,可能就会引发悲剧——大胖子整个人被吸在坐便器上动弹不得。
解决这个问题最好的办法,就是将冲洗按钮设计在坐便器之后——这样,人们必须站起来而后按下冲洗按钮。这是因为,「被吸住」的前提是有一个大胖子「坐在」坐便器上按下冲洗按钮;将按钮设计在身后,破坏了「坐在」坐便器上这个前提,因而一劳永逸地解决了这个问题。
对于资源,我们希望的是当使用完毕之后释放。而出现资源泄露的根本问题在于,我们很难穷举所有「使用完毕」的情形;而但凡有一种情形我们没有处理好,那么在这种情形下,就可能出现资源泄漏。如果想要一劳永逸地解决这个问题,我们就有必要仔细思考:在 C++ 中,有哪些东西是天然地在使用完毕之后,就会被释放的。对于任何一个稍有 C++ 经验的程序员来说,答案都是呼之欲出的:局部变量。
保存在 stack 上的局部变量,由系统维护。当局部变量的生存期完结,它就会被自动销毁。因此,若是将资源的获取与局部变量的初始化绑定在一起(此即 RAII),我们就能放心地使用资源,而不必担心资源泄漏问题。(智能指针就是这样做的)例如,对于文件指针来说,我们可以有这样的定义
1 | class FileHandle { |
至此,我们就能放心地使用 FileHandle 来管理文件资源了(其他类型的资源也可以类似地定义)。


