网上有一个流传多年的段子。这个段子大致是说,若你在简体中文版本的 Windows 系统下,用系统自带的记事本程序,以默认的 ANSI 编码保存「联通」两个字,那么重新打开后「联通」二字就消失了。如果我没记错的话,还曾有好事者据此编排,认定 Windows 背后的微软和联通有仇,故意不让联通二字正常显示。
当然,这个说法肯定是假的。但是这一现象背后的原因究竟是什么呢?实际上,网络上也有不少文章专门解释了这个问题。虽然以我的经验,能够看懂。但是若是「三秒变小白」,这些文章就不令人满意了。这是此文的缘由。
在介绍 Windows 记事本乱码问题之前,我们先来了解一些基础知识。
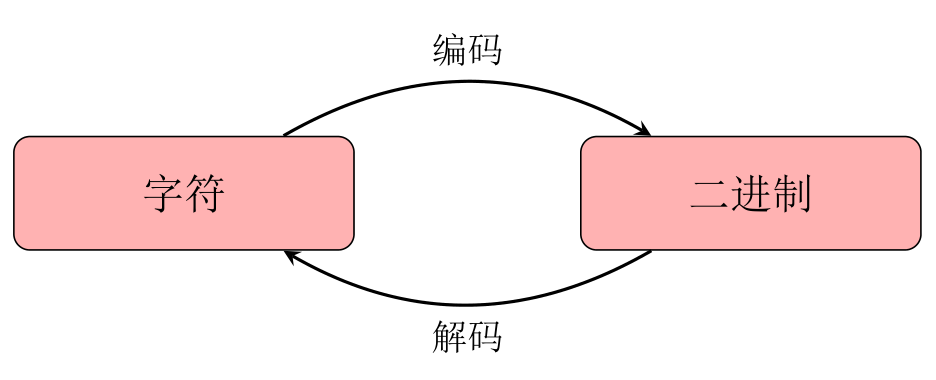
字符集及其编码与解码 编码与解码 所谓编码,就是一种规则,或者说是一种映射关系。它描述了在含义上相同的事物,如何以两种不同的形式表示出来。同一个事物按照编码从一种形式转换成另一种形式的过程,则是编码过程。
这个概念很重要,你可以酌情多读几遍。
例如说,在密码学当中,加密的过程,就是一种编码的过程。在加密体系当中,明文和密文,在含义上是相同的,但是表现形式却不同。明文是人类能够识别的语言,而密文在人类看起来则是莫名其妙的一串字符。又例如说,翻译的过程,也是一种编码的过程。翻译工作者将一句话从英文翻译成中文时,两个句子的含义是相同的,但是表现形式却不同。
和编码过程对应的是解码过程。从编码过程的定义中不难发现,编码规则两端的两种形式,在抽象上是地位等同的。所谓编码和解码的「方向」其实只是认为规定的而已。这在「翻译」的例子中很容易体现:从中文翻译到英文、从英文翻译到中文,二者谁是编码、谁是解码,其实只是具体场景下的约定。当然,在特定的领域,编码和解码是有约定俗成的。例如从明文到密文,约定俗成为编码过程;反过来从密文到明文,约定俗成是解码过程。若是反过来,从概念上当然不是不可以,但是未免让别人难以理解。
字符集 人类的语言以字符承载。然而,众所周知,二进制的计算机是无法直接理解这些字符的。在计算机里,不论何种语言的字符,都是以二进制的形式保存、传输、交换的。这就牵扯到字符的编码和解码问题了:同样含义的字符,如何在人类理解的形状这一形式与计算机内部的二进制形式之间做出对应呢?
不过,在回答这个问题之前,还有一个更基本的问题需要解答:当计算机遭遇字符,我们到底需要计算机表示哪些字符?
这就引出了字符集(Charset)的概念。通常来说,字符集是一类字符按照一定方式编号排成的表格。比如,中国为汉字曾陆续制定了多个字符集:GB2312、GBK、GB18030;其中 GBK 字符集收录了 21886 个汉字和图形符号。又例如,Unicode 对世界上大多数文字系统进行了同一的整理和编码,因此正在逐渐成为计算机领域内的事实标准。
字符编码 有了字符集,人们就可以基于其上制定字符与二进制表示(实际上就是数字)的编码规则了。这些规则,就是字符编码。
很显然,因为字符集本身就带有一组编号。因此,字符集本身也能直接用于字符编码。例如,ASCII 既是字符集,也是字符编码;GBK 也是同样。对于这种情况,字符集和字符编码合二为一,没有任何区别。因此,当人们讲「GBK 编码」的时候,替换成「GBK 字符集」基本上不影响表意。
还有一些字符编码规则,则是基于字符集之上的。这些字符编码,以某种特定的方式,规定了字符集内所有字符的编码规则。例如说,基于 Unicode 字符集,流行的编码规则有 UTF-8、UTF-16、UTF-32 等。它们为所有 Unicode 字符集中的字符指定了编码规则,但又与 Unicode 字符集中的编号不(完全)一致。因此,这种情况下,Unicode 字符集和 UTF-8 等三种编码不能划等号。
Windows 系统记事本里的「Unicode 编码」实际上是「带有 BOM 的小端序 UTF-16」。这意味着 Windows 将 Unicode 字符集和 UTF-16 划上了等号。这实际是不对的。
UTF-8 编码 按照 Wikipedia 的介绍 ,UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码。它可以用来表示Unicode标准中的任何字符,且其编码中的第一个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。因此,它逐渐成为电子邮件、网页及其他存储或发送文字的应用中,优先采用的编码。
和 UTF-16 和 UTF-32 不同,UTF-8 采用了特别的编码规则,因此不存在「大端序」和「小端序」的差异。
码点位数
码点起始值
码点终止值
字节序列长度
Byte 1
Byte 2
Byte 3
Byte 4
Byte 5
Byte 6
7
U+00
U+7F
1
0xxxxxxx-
-
-
-
-
11
U+0080
U+07FF
2
110xxxxx10xxxxxx-
-
-
-
16
U+0800
U+FFFF
3
1110xxxx10xxxxxx10xxxxxx-
-
-
21
U+10000
U+1FFFFF
4
11110xxx10xxxxxx10xxxxxx10xxxxxx-
-
26
U+200000
U+3FFFFFF
5
111110xx10xxxxxx10xxxxxx10xxxxxx10xxxxxx-
31
U+4000000
U+7FFFFFFF
6
1111110x10xxxxxx10xxxxxx10xxxxxx10xxxxxx10xxxxxx
具体来说,UTF-8 编码的结果,其长度是变长的。但是,除了每个字符编码的「第一个字节」之外,其余所有字节,二进制表示都以 10 开始。这样,每个字符的第一个字节就变得特殊起来。
一方面,首字节不以 10 开始,表达了「字符开始」这一信息;
另一方面,除了 ASCII 范围内的单字节编码,其余多字节编码时,首字节的开始有多少位 1,就记录了这个字符占了多少个字节。
因此,一方面,如果一篇文档只包含 ASCII 字符,那么 UTF-8 编码和 ASCII 编码得到的结果完全相同。这就保证了兼容性。另一方面,这样的编码规则保证了字节顺序的确定性,因此没有大端序和小端序的差异,也就不需要 BOM。
Windows 记事本都做了什么 这里着重感谢 margen 对 Windows 记事本程序做的逆向工作。没有他的工作,本文不至于这样精彩。光荣属于前辈!
保存的过程 根据 margen 的逆向分析 ,在打开文件的过程中,记事本程序会调用 fDetermineFileType 来判断文件的编码类型。翻译成 C 语言代码,大致如下。,Windows 记事本在以 ANSI 保存文件时,没有任何多余的动作,直接将 buffer 中的内容通过 WriteFile 系统调用写入到 txt 文件当中。
我们以 010editor 打开保存了「联通」二字文件看看。
可以看到,在简体中文 Windows 下,以记事本保存「联通」两个字。那么保存得到的 txt 文件内,就仅有 0xC1AACDA8 这些内容。而 0xC1AA 和 0xCDA8 正是「联通」两个字的 GBK 编码。
打开的过程 根据 margen 的逆向分析 ,在打开文件的过程中,记事本程序会调用 fDetermineFileType 来判断文件的编码类型。翻译成 C 语言代码,大致如下。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 int __stdcall fDetermineFileType (LPVOID lpBuffer,int cb) { int iType = 0 ; WORD wSign = 0 ; if ( cb <= 1 ) return 0 ; wSign = *(PWORD)lpBuffer; switch ( wSign ) { case 0xBBEF : { if ( cb >= 3 && (PBYTE)lpBuffer[3 ] == 0xBF ) iType = 3 ; } break ; case 0xFEFF : { iType = 1 ; } break ; case 0xFFFE : { iType = 2 ; } break ; default : { if ( !IsInputTextUnicode( lpBuffer, cb ) ) { if ( IsTextUTF8( lpBuffer, cb ) ) iType = 3 ; } else iType = 1 ; } } return iType; }
首先,代码从文件头部取出了前 2 个字节,然后走 switch 分支判断。
若前两个字节是 0xBBEF,且文件第三个字节是 0xBF,则组成 UTF-8 的 BOM(虽然 UTF-8 不需要)。那么据此判断文件编码是 UTF-8。
若前两个字节是 0xFEFF,那么这是小端序 UTF-16 的 BOM。据此判断文件编码是(Windows 所谓的)Unicode 编码。
若前两个字节是 0xFFFE,那么这是大端序的 UTF-16 的 BOM。据此判断文件编码是(Windows 所谓的)Unicode Big Endian 编码。
否则,则需要做更深层次的判断。注意到,iType 被初始化为 0,代表 ANSI 编码(简体中文下是 CP936,相当于是 GBK 编码)。若已走到了 default 分支,要函数返回 0,当且仅当 IsTextUTF8( lpBuffer, cb ) 为 false 才行。然而,这个函数的写法是这样的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 BOOL IsTextUTF8 ( LPSTR lpBuffer, int iBufSize ) { int iLeftBytes = 0 ; BOOL bUtf8 = FALSE; if ( iBufSize <= 0 ) return FALSE; for ( int i=0 ;i<iBufSize;i++) { char c = lpBuffer[i]; if ( c < 0 ) bUtf8 = TRUE; if ( iLeftBytes == 0 ) { if ( c >= 0 ) continue ; do { c <<= 1 ; iLeftBytes++; } while ( c < 0 ); iLeftBytes--; if ( iLeftBytes == 0 ) return FALSE; } else { c &= 0xC0 ; if ( c != (char )0x80 ) return FALSE; else iLeftBytes--; } } if ( iLeftBytes ) return FALSE; return bUtf8; }
我们重点看 for 循环内部的逻辑。首先,char c = lpBuffer[i]; 从 buffer 中取出一个字节,保存在 signed char 当中。而后判断 if( c < 0 )。因为 c 是有符号的 char,所以 c < 0 意味着最高位是 1。这就意味着该字符肯定不是 ASCII 字符,可能是一个 UTF-8 字符。因此将 bUtf8 置为 true。
而后,在 if( iLeftBytes == 0 ) 分支中,我们看到 c <<= 1; iLeftBytes++; 的 do-while 循环。这是在判断 UTF-8 编码的首字符中,有多少个前缀的 1。根据 UTF-8 的编码规则,这个数值就是该 UTF-8 字符的编码长度,记录在 iLeftBytes 当中。
接下来,根据 iLeftBytes 的大小,逐一检查后续的字节,是否以 10 开头。一旦发现有不满足条件的字节,就能判定当前文档不是 UTF-8 编码的。或是(在 for 循环结束之后)发现 iLeftBytes 尚未自减到 0 就已经到了文档末尾,则也可以判定当前文档不是 UTF-8 编码的。
也就是说,这个函数的逻辑,是根据 UTF-8 编码规则,全文扫描。若发现有一个字符不符合 UTF-8 的编码规则,则返回 false;否则若全文都符合 UTF-8 的编码规则,则返回 true。
「联通」都经历了什么? 回过头,我们看到,联通二字以 ANSI(CP936)保存的 txt 文件里只有 0xC1AACDA8 这些内容。因为无有 BOM,所以在 fDetermineFileType 函数中必然走到 default 分支,而后陷入 IsTextUTF8 函数当中。
不巧的是,0xC1AA 和 0xCDA8 都符合 UTF-8 编码的要求。因此该函数返回 true。于是,Windows 记事本打开这一文件时,认定这是一个无 BOM 的 UTF-8 编码的文件。于是按照 UTF-8 编码去解读 0xC1AACDA8,那么就乱码了。
还有哪些字符 从前文的分析,我们可以得到结论:如果一个以 ANSI(CP936/GBK)保存的文档,内里包含的所有字符,都不幸满足了 UTF-8 的编码规则。那么这个文档将被 Windows 记事本当做是 UTF-8 编码的文件打开,就会乱码。
由于 GBK 是双字节的编码格式,只可能满足 UTF-8 中对 U+0080 至 U+07FF 编码的格式:110xxxxx, 10xxxxxx。我们可以将这些字符全都扫描输出出来。以下是完成这一任务的 Python 代码。
1 2 3 4 5 6 7 8 9 10 11 pluses = map (lambda i:"+%s" % (hex (i)[2 :].upper()), xrange(16 )) headline = "%s%s" % (" " * 7 , " " .join(pluses)) print headlinefor i in xrange(192 , 224 ): high = hex (i)[2 :].upper() for j in xrange(4 ): low = hex (128 + j * 16 )[2 :].upper() chars = map (lambda k:(chr (i) + chr (128 + j * 16 + k)).decode("gbk" ), xrange(16 )) line = u"0x%s%s %s" % (high, low, " " .join(chars)) print line
得到的结果是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 +0 +1 +2 +3 +4 +5 +6 +7 +8 +9 +A +B +C +D +E +F 0xC080 纮 纴 纻 纼 绖 绤 绬 绹 缊 缐 缞 缷 缹 缻 缼 缽 0xC090 缾 缿 罀 罁 罃 罆 罇 罈 罉 罊 罋 罌 罍 罎 罏 罒 0xC0A0 罓 馈 愧 溃 坤 昆 捆 困 括 扩 廓 阔 垃 拉 喇 蜡 0xC0B0 腊 辣 啦 莱 来 赖 蓝 婪 栏 拦 篮 阑 兰 澜 谰 揽 0xC180 羳 羴 羵 羶 羷 羺 羻 羾 翀 翂 翃 翄 翆 翇 翈 翉 0xC190 翋 翍 翏 翐 翑 習 翓 翖 翗 翙 翚 翛 翜 翝 翞 翢 0xC1A0 翣 痢 立 粒 沥 隶 力 璃 哩 俩 联 莲 连 镰 廉 怜 0xC1B0 涟 帘 敛 脸 链 恋 炼 练 粮 凉 梁 粱 良 两 辆 量 0xC280 聙 聛 聜 聝 聞 聟 聠 聡 聢 聣 聤 聥 聦 聧 聨 聫 0xC290 聬 聭 聮 聯 聰 聲 聳 聴 聵 聶 職 聸 聹 聺 聻 聼 0xC2A0 聽 隆 垄 拢 陇 楼 娄 搂 篓 漏 陋 芦 卢 颅 庐 炉 0xC2B0 掳 卤 虏 鲁 麓 碌 露 路 赂 鹿 潞 禄 录 陆 戮 驴 0xC380 脌 脕 脗 脙 脛 脜 脝 脟 脠 脡 脢 脣 脤 脥 脦 脧 0xC390 脨 脩 脪 脫 脭 脮 脰 脳 脴 脵 脷 脹 脺 脻 脼 脽 0xC3A0 脿 谩 芒 茫 盲 氓 忙 莽 猫 茅 锚 毛 矛 铆 卯 茂 0xC3B0 冒 帽 貌 贸 么 玫 枚 梅 酶 霉 煤 没 眉 媒 镁 每 0xC480 膧 膩 膫 膬 膭 膮 膯 膰 膱 膲 膴 膵 膶 膷 膸 膹 0xC490 膼 膽 膾 膿 臄 臅 臇 臈 臉 臋 臍 臎 臏 臐 臑 臒 0xC4A0 臓 摹 蘑 模 膜 磨 摩 魔 抹 末 莫 墨 默 沫 漠 寞 0xC4B0 陌 谋 牟 某 拇 牡 亩 姆 母 墓 暮 幕 募 慕 木 目 0xC580 艀 艁 艂 艃 艅 艆 艈 艊 艌 艍 艎 艐 艑 艒 艓 艔 0xC590 艕 艖 艗 艙 艛 艜 艝 艞 艠 艡 艢 艣 艤 艥 艦 艧 0xC5A0 艩 拧 泞 牛 扭 钮 纽 脓 浓 农 弄 奴 努 怒 女 暖 0xC5B0 虐 疟 挪 懦 糯 诺 哦 欧 鸥 殴 藕 呕 偶 沤 啪 趴 0xC680 苺 苼 苽 苾 苿 茀 茊 茋 茍 茐 茒 茓 茖 茘 茙 茝 0xC690 茞 茟 茠 茡 茢 茣 茤 茥 茦 茩 茪 茮 茰 茲 茷 茻 0xC6A0 茽 啤 脾 疲 皮 匹 痞 僻 屁 譬 篇 偏 片 骗 飘 漂 0xC6B0 瓢 票 撇 瞥 拼 频 贫 品 聘 乒 坪 苹 萍 平 凭 瓶 0xC780 莯 莵 莻 莾 莿 菂 菃 菄 菆 菈 菉 菋 菍 菎 菐 菑 0xC790 菒 菓 菕 菗 菙 菚 菛 菞 菢 菣 菤 菦 菧 菨 菫 菬 0xC7A0 菭 恰 洽 牵 扦 钎 铅 千 迁 签 仟 谦 乾 黔 钱 钳 0xC7B0 前 潜 遣 浅 谴 堑 嵌 欠 歉 枪 呛 腔 羌 墙 蔷 强 0xC880 葊 葋 葌 葍 葎 葏 葐 葒 葓 葔 葕 葖 葘 葝 葞 葟 0xC890 葠 葢 葤 葥 葦 葧 葨 葪 葮 葯 葰 葲 葴 葷 葹 葻 0xC8A0 葼 取 娶 龋 趣 去 圈 颧 权 醛 泉 全 痊 拳 犬 券 0xC8B0 劝 缺 炔 瘸 却 鹊 榷 确 雀 裙 群 然 燃 冉 染 瓤 0xC980 蓘 蓙 蓚 蓛 蓜 蓞 蓡 蓢 蓤 蓧 蓨 蓩 蓪 蓫 蓭 蓮 0xC990 蓯 蓱 蓲 蓳 蓴 蓵 蓶 蓷 蓸 蓹 蓺 蓻 蓽 蓾 蔀 蔁 0xC9A0 蔂 伞 散 桑 嗓 丧 搔 骚 扫 嫂 瑟 色 涩 森 僧 莎 0xC9B0 砂 杀 刹 沙 纱 傻 啥 煞 筛 晒 珊 苫 杉 山 删 煽 0xCA80 蕗 蕘 蕚 蕛 蕜 蕝 蕟 蕠 蕡 蕢 蕣 蕥 蕦 蕧 蕩 蕪 0xCA90 蕫 蕬 蕭 蕮 蕯 蕰 蕱 蕳 蕵 蕶 蕷 蕸 蕼 蕽 蕿 薀 0xCAA0 薁 省 盛 剩 胜 圣 师 失 狮 施 湿 诗 尸 虱 十 石 0xCAB0 拾 时 什 食 蚀 实 识 史 矢 使 屎 驶 始 式 示 士 0xCB80 藔 藖 藗 藘 藙 藚 藛 藝 藞 藟 藠 藡 藢 藣 藥 藦 0xCB90 藧 藨 藪 藫 藬 藭 藮 藯 藰 藱 藲 藳 藴 藵 藶 藷 0xCBA0 藸 恕 刷 耍 摔 衰 甩 帅 栓 拴 霜 双 爽 谁 水 睡 0xCBB0 税 吮 瞬 顺 舜 说 硕 朔 烁 斯 撕 嘶 思 私 司 丝 0xCC80 虁 虂 虃 虄 虅 虆 虇 虈 虉 虊 虋 虌 虒 虓 處 虖 0xCC90 虗 虘 虙 虛 虜 虝 號 虠 虡 虣 虤 虥 虦 虧 虨 虩 0xCCA0 虪 獭 挞 蹋 踏 胎 苔 抬 台 泰 酞 太 态 汰 坍 摊 0xCCB0 贪 瘫 滩 坛 檀 痰 潭 谭 谈 坦 毯 袒 碳 探 叹 炭 0xCD80 蛝 蛠 蛡 蛢 蛣 蛥 蛦 蛧 蛨 蛪 蛫 蛬 蛯 蛵 蛶 蛷 0xCD90 蛺 蛻 蛼 蛽 蛿 蜁 蜄 蜅 蜆 蜋 蜌 蜎 蜏 蜐 蜑 蜔 0xCDA0 蜖 汀 廷 停 亭 庭 挺 艇 通 桐 酮 瞳 同 铜 彤 童 0xCDB0 桶 捅 筒 统 痛 偷 投 头 透 凸 秃 突 图 徒 途 涂 0xCE80 蝷 蝸 蝹 蝺 蝿 螀 螁 螄 螆 螇 螉 螊 螌 螎 螏 螐 0xCE90 螑 螒 螔 螕 螖 螘 螙 螚 螛 螜 螝 螞 螠 螡 螢 螣 0xCEA0 螤 巍 微 危 韦 违 桅 围 唯 惟 为 潍 维 苇 萎 委 0xCEB0 伟 伪 尾 纬 未 蔚 味 畏 胃 喂 魏 位 渭 谓 尉 慰 0xCF80 蟺 蟻 蟼 蟽 蟿 蠀 蠁 蠂 蠄 蠅 蠆 蠇 蠈 蠉 蠋 蠌 0xCF90 蠍 蠎 蠏 蠐 蠑 蠒 蠔 蠗 蠘 蠙 蠚 蠜 蠝 蠞 蠟 蠠 0xCFA0 蠣 稀 息 希 悉 膝 夕 惜 熄 烯 溪 汐 犀 檄 袭 席 0xCFB0 习 媳 喜 铣 洗 系 隙 戏 细 瞎 虾 匣 霞 辖 暇 峡 0xD080 衻 衼 袀 袃 袆 袇 袉 袊 袌 袎 袏 袐 袑 袓 袔 袕 0xD090 袗 袘 袙 袚 袛 袝 袞 袟 袠 袡 袣 袥 袦 袧 袨 袩 0xD0A0 袪 小 孝 校 肖 啸 笑 效 楔 些 歇 蝎 鞋 协 挟 携 0xD0B0 邪 斜 胁 谐 写 械 卸 蟹 懈 泄 泻 谢 屑 薪 芯 锌 0xD180 褉 褋 褌 褍 褎 褏 褑 褔 褕 褖 褗 褘 褜 褝 褞 褟 0xD190 褠 褢 褣 褤 褦 褧 褨 褩 褬 褭 褮 褯 褱 褲 褳 褵 0xD1A0 褷 选 癣 眩 绚 靴 薛 学 穴 雪 血 勋 熏 循 旬 询 0xD1B0 寻 驯 巡 殉 汛 训 讯 逊 迅 压 押 鸦 鸭 呀 丫 芽 0xD280 襽 襾 覀 覂 覄 覅 覇 覈 覉 覊 見 覌 覍 覎 規 覐 0xD290 覑 覒 覓 覔 覕 視 覗 覘 覙 覚 覛 覜 覝 覞 覟 覠 0xD2A0 覡 摇 尧 遥 窑 谣 姚 咬 舀 药 要 耀 椰 噎 耶 爷 0xD2B0 野 冶 也 页 掖 业 叶 曳 腋 夜 液 一 壹 医 揖 铱 0xD380 觻 觼 觽 觾 觿 訁 訂 訃 訄 訅 訆 計 訉 訊 訋 訌 0xD390 訍 討 訏 訐 訑 訒 訓 訔 訕 訖 託 記 訙 訚 訛 訜 0xD3A0 訝 印 英 樱 婴 鹰 应 缨 莹 萤 营 荧 蝇 迎 赢 盈 0xD3B0 影 颖 硬 映 哟 拥 佣 臃 痈 庸 雍 踊 蛹 咏 泳 涌 0xD480 詟 詠 詡 詢 詣 詤 詥 試 詧 詨 詩 詪 詫 詬 詭 詮 0xD490 詯 詰 話 該 詳 詴 詵 詶 詷 詸 詺 詻 詼 詽 詾 詿 0xD4A0 誀 浴 寓 裕 预 豫 驭 鸳 渊 冤 元 垣 袁 原 援 辕 0xD6A0 譅 帧 症 郑 证 芝 枝 支 吱 蜘 知 肢 脂 汁 之 织 0xD6B0 职 直 植 殖 执 值 侄 址 指 止 趾 只 旨 纸 志 挚 0xD780 讇 讈 讉 變 讋 讌 讍 讎 讏 讐 讑 讒 讓 讔 讕 讖 0xD790 讗 讘 讙 讚 讛 讜 讝 讞 讟 讬 讱 讻 诇 诐 诪 谉 0xD7A0 谞 住 注 祝 驻 抓 爪 拽 专 砖 转 撰 赚 篆 桩 庄 0xD7B0 装 妆 撞 壮 状 椎 锥 追 赘 坠 缀 谆 准 捉 拙 卓 0xD880 貈 貋 貍 貎 貏 貐 貑 貒 貓 貕 貖 貗 貙 貚 貛 貜 0xD890 貝 貞 貟 負 財 貢 貣 貤 貥 貦 貧 貨 販 貪 貫 責 0xD8A0 貭 亍 丌 兀 丐 廿 卅 丕 亘 丞 鬲 孬 噩 丨 禺 丿 0xD8B0 匕 乇 夭 爻 卮 氐 囟 胤 馗 毓 睾 鼗 丶 亟 鼐 乜 0xD980 賭 賮 賯 賰 賱 賲 賳 賴 賵 賶 賷 賸 賹 賺 賻 購 0xD990 賽 賾 賿 贀 贁 贂 贃 贄 贅 贆 贇 贈 贉 贊 贋 贌 0xD9A0 贍 佟 佗 伲 伽 佶 佴 侑 侉 侃 侏 佾 佻 侪 佼 侬 0xD9B0 侔 俦 俨 俪 俅 俚 俣 俜 俑 俟 俸 倩 偌 俳 倬 倏 0xDA80 趢 趤 趥 趦 趧 趨 趩 趪 趫 趬 趭 趮 趯 趰 趲 趶 0xDA90 趷 趹 趻 趽 跀 跁 跂 跅 跇 跈 跉 跊 跍 跐 跒 跓 0xDAA0 跔 凇 冖 冢 冥 讠 讦 讧 讪 讴 讵 讷 诂 诃 诋 诏 0xDAB0 诎 诒 诓 诔 诖 诘 诙 诜 诟 诠 诤 诨 诩 诮 诰 诳 0xDB80 踿 蹃 蹅 蹆 蹌 蹍 蹎 蹏 蹐 蹓 蹔 蹕 蹖 蹗 蹘 蹚 0xDB90 蹛 蹜 蹝 蹞 蹟 蹠 蹡 蹢 蹣 蹤 蹥 蹧 蹨 蹪 蹫 蹮 0xDBA0 蹱 邸 邰 郏 郅 邾 郐 郄 郇 郓 郦 郢 郜 郗 郛 郫 0xDBB0 郯 郾 鄄 鄢 鄞 鄣 鄱 鄯 鄹 酃 酆 刍 奂 劢 劬 劭 0xDC80 軃 軄 軅 軆 軇 軈 軉 車 軋 軌 軍 軏 軐 軑 軒 軓 0xDC90 軔 軕 軖 軗 軘 軙 軚 軛 軜 軝 軞 軟 軠 軡 転 軣 0xDCA0 軤 堋 堍 埽 埭 堀 堞 堙 塄 堠 塥 塬 墁 墉 墚 墀 0xDCB0 馨 鼙 懿 艹 艽 艿 芏 芊 芨 芄 芎 芑 芗 芙 芫 芸 0xDD80 輤 輥 輦 輧 輨 輩 輪 輫 輬 輭 輮 輯 輰 輱 輲 輳 0xDD90 輴 輵 輶 輷 輸 輹 輺 輻 輼 輽 輾 輿 轀 轁 轂 轃 0xDDA0 轄 荨 茛 荩 荬 荪 荭 荮 莰 荸 莳 莴 莠 莪 莓 莜 0xDDB0 莅 荼 莶 莩 荽 莸 荻 莘 莞 莨 莺 莼 菁 萁 菥 菘 0xDE80 迉 迊 迋 迌 迍 迏 迒 迖 迗 迚 迠 迡 迣 迧 迬 迯 0xDE90 迱 迲 迴 迵 迶 迺 迻 迼 迾 迿 逇 逈 逌 逎 逓 逕 0xDEA0 逘 蕖 蔻 蓿 蓼 蕙 蕈 蕨 蕤 蕞 蕺 瞢 蕃 蕲 蕻 薤 0xDEB0 薨 薇 薏 蕹 薮 薜 薅 薹 薷 薰 藓 藁 藜 藿 蘧 蘅 0xDF80 還 邅 邆 邇 邉 邊 邌 邍 邎 邏 邐 邒 邔 邖 邘 邚 0xDF90 邜 邞 邟 邠 邤 邥 邧 邨 邩 邫 邭 邲 邷 邼 邽 邿 0xDFA0 郀 摺 撷 撸 撙 撺 擀 擐 擗 擤 擢 攉 攥 攮 弋 忒 0xDFB0 甙 弑 卟 叱 叽 叩 叨 叻 吒 吖 吆 呋 呒 呓 呔 呖
若一个文档里只包含这个表格中的汉字(可以再包含 ASCII 字符),在简体中文 Windows 下在记事本中以 ANSI 编码保存,则再次打开必然乱码。特别地,这个表格本身也会乱码。
据此,你可以构造出各种跟微软「有仇」的文档。比如「联通」,比如「小泉水」。