Linux 的线程设计十分优美:线程只不过是共享虚拟地址空间和文件描述符表的进程而已。由某一进程产生的线程是该主线程(父进程)的子进程。除了少数线程相关的系统调用,操作线程的系统调用与操作进程的系统调用完全相同。这种优美与文件描述符的优美异曲同工。
通常来说,在类-Unix 的系统上,进程是通过 fork() 来生成的。新生成的进程的虚拟内存空间是原进程的拷贝,但具有独立的地址空间和文件描述符表。(Linux 使用写时拷贝技术提升了这一步骤的效率)不过,对于创建线程来说,这种做法太高级(high-level)了;因此 Linux 还有名为 clone() 的系统调用。它与 fork() 的行为大致相同,只不过它能通过一系列参数控制其行为:主要是控制子进程与父进程之间共享那些运行时上下文。
在进程的栈上创建一个新的线程非常简单——只需要 15 条命令,而无需任何库,特别是不需要调用 pthread 库!本文中,我将以 x86-64 平台为例。所有代码均以 NASM 语法写就,因为,依我愚见,它是至今为止最好的(参见:这里)。
此处是完整的示例代码:Pure assembly, library-free Linux threading demo。
x86-64 启蒙
为了在你不熟悉 x86-64 汇编的情况下能够读完本文,此处给出 x86-64 中相关内容的启蒙教程。若你对这些内容很熟悉,则可跳过本节。
x86-64 有 16 个 64 位通用寄存器(general purpose registers)。它们主要被用来操作包括内存地址在内的整数。除此之外,还有很多有各种用途的寄存器;不过它们与线程没什么关系。
rsp:栈指针rbp:基指针(在排错和效能分析中仍有用到)raxrbxrcxrdx:通用寄存器(注意a,b,c,d)rdirsi:d和s分别表示 “destination” 和 “source”,不过现在已经没有意义了r8r9r10r11r12r13r14r15:在 x86-64 中新增的寄存器
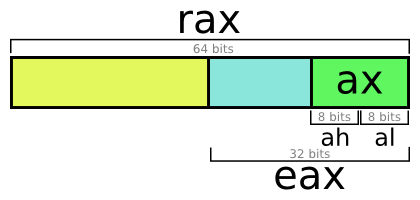
前缀 r 表明它们是 64 位寄存器。虽与本文主旨无关,但仍然提一句:前缀 e 表示同一寄存器的最低 32 位,以及没有前缀的则表示同一寄存器的最低 16 位。这是因为 x86 最早是 16 位的,后来扩展到 32 位,又扩展到 64 位。历史上这些寄存器都有专门的用途,但是在 x86-64 上,它们基本上是地位等同的。
还有一个名为 rip 的指令指针寄存器。概念上说,在程序执行时,它随着执行过程遍历进程空间中的机器指令。尽管它的特别之处在于它无法被直接操作,而只能被间接修改;但考虑到代码和数据处于同一地址空间中,rip 和其他数据指针也就没什么区别了。
栈(stack)
rsp 寄存器指向调用栈的「栈顶」。调用栈始终追踪着当前函数的调用者,以及局部变量和函数状态(这是栈帧保存的内容)。之所以「栈顶」打上了引号,是因为在 x86 中,栈实际上是往地址较低的方向生长的,因此栈指针指向栈的最低有效地址。这部分信息在讨论线程时十分关键,因为在生成线程时我们要在栈上分配内存。
有时栈也被用来向其他函数传参。在 x86-64 上,这种情况甚少发生,尤其是在 Linux 使用的 System V 二进制接口中:前 6 个参数通过寄存器传参。函数的返回值则通过 rax 寄存器返回。当函数调用发生时,整型变量/指针按照如下顺序通过寄存器传递:rdi, rsi, rdx, rcx, r8, r9。
因此,举例来说,当调用 foo(1, 2, 3) 时,参数 1, 2, 3 会被分别保存在 rdi, rsi 和 rdx 三个寄存器当中。mov 指令将第二个操作数的值保存在第一个操作数(寄存器名称)中。call 指令将 rip 寄存器的当前值压栈,而后将 rip 设置为目标函数的起始地址(跳转)。当被调用的函数执行完毕准备返回时,它会使用 ret 指令将 rip 寄存器的原始值弹栈并保存在 rip 寄存器当中,以将程序的控制权交还给调用者。
1 | mov rdi, 1 |
在被调用函数返回时,它还必须保证下列寄存器的值与被调用前保持一致:rbx, rsp, rbp, r12, r13, r14, r15。
系统调用
执行系统调用时,用于传参的寄存器稍有不同。注意,rcx 换成了 r10:rdi, rsi, rdx, r10, r8, r9。
每个系统调用都有一个整数标识符。在不同平台上,系统调用的编号可能不同。不过,在 Linux 中,这些标识符是永远不会变的。与 call 指令不同,在 syscall 指令之前,相应的系统调用编号需要保存在 rax 当中,而后由 syscall 指令向系统内核发起系统调用请求。在 x86-64 之前,系统调用是通过旧式的中断来实现的。因为中断效率低下,旧式的中断先后被一个特别的静态定位的 vsyscall 帧(现在因为安全风险而弃用)和 vDSO 所代替,使得一些系统调用能像普通函数调用那样被调用。在本文中,我们只需要 syscall 指令即可。
因此,例如说系统调用 write() 有如下 C 函数原型。
1 | ssize_t write(int fd, const void *buf, size_t count); |
在 x86-64 中,系统调用 write() 位于系统调用表的顶端,编号为 1(编号为 0 的是系统调用 read())。标准输出的文件描述符是 1(标准输入是 0)。下面的代码将从内存地址 buffer 中(在汇编程序其他位置定义的符号)读取 10 字节的内容写至标准输出。成功写入的字节数将被保存在 rax 中返回;若返回 -1,则表示出现错误。
1 | mov rdi, 1 ; fd |
有效地址
还有最后一个知识点:寄存器通常保存着内存地址(也就是一个指针),而你需要有办法读取这一地址中保存的内容。在 NASM 语法中,用方括号包裹寄存器的名字(例如 [rax])和 C 中对指针进行解引用是一个效果。
这些方括号表达式被称为有效地址。在单条指令中,方括号内可以有有限的算数表达式去计算基地址之上的偏移量。这种表达式内可以有另一个寄存器(index)、一个 2 的幂方的标量(按位移动)以及一个有符号的偏移量。比如对于该表达式:[rax + rdx * 8 + 12];如果 rax 是一个指向结构体的指针,rdx 是结构体内数组内某一元素的索引,则读取该元素只需要一条指令即可。NASM 聪明地扩展了有效地址表达式,它允许汇编程序员写出超出上述模式的表达式。例如:[base + index * 2 ^ exp + offset]。
本文不关注寻址的细节,因此如果搞不懂它也没关系。
分配栈
线程之间共享除寄存器、栈、线程内本地存储(thread-local storage, TLS)之外的所有东西。操作系统和底层硬件天然地保证了线程不会共享寄存器;而由于 TLS 不是必须的,所以本文也不表 TLS 相关操作——在实践中,通常会将栈作为 TLS 使用。因此,我们需要特别处理的就是栈了。在创建线程之前,我们必须先为之分配一个栈。当然,这种栈不仅仅是内存缓冲区那么简单。
最平凡的方式是在可执行程序的 .bss 段(全零初始化)中为线程保留固定长度的存储空间。但我希望如 pthread 之类的线程库那样,以正确的方式动态分配栈空间。否则,应用程序所能支持的线程数量在编译期就会被限制死了。
在虚拟内存空间内你不能直接的任意地址上读取或写入,而是必须向操作系统请求分配内存页帧。Linux 系统中有两个系统调用能实现我们的需求:
brk():扩展或缩减执行中进程的堆的大小。堆通常在.bss端后不远处;许多分配器会在分配少量内存或初始化时这样做。考虑到栈是向下生长的,而brk()在默认情况下不会设置保护页帧,栈的生长可能会破坏临近的重要数据,因而这不是一个很好的选择。这种情况下,攻击者的实施栈溢出会更加容易。所谓保护页帧是位于栈空间尾部的页帧,它被锁住,并且在栈溢出时会触发段错误,而不会让栈溢出的数据破坏其他内存数据。当然,也可以用系统调用mprotect()手工创建一个保护页帧。除了保护页帧的问题之外,这种方式设置的线程栈无法继续生长,也是一个问题。
mmap():使用匿名映射,在随机内存地址上分配一组连续的内存页帧。如我们即将看到的,你可以明确告诉内核,这部分内存将被用来做线程的栈。这比使用系统调用brk()来得简单。
在 x86-64 中,系统调用 mmap() 的编号是 9。我将以如下 C 函数原型来分配一个线程栈。
1 | void *stack_create(void); |
系统调用 mmap() 需要 6 个参数。不过在创建匿名内存映射时,最后两个参数会被忽略掉。对于我们的需求来说,它有如下 C 函数原型。
1 | void *mmap(void *addr, size_t length, int prot, int flags); |
对于 flags,考虑到我们将用这块内存作为线程栈,我们将选择私有、匿名、向下生长。不过,哪怕设置了向下生长,系统调用 mmap() 仍然会返回内存映射的底部地址。一会儿会用到这一重要信息。于是,事情就简单了:只需要将寄存器的值设置好,而后执行 syscall 指令即可。
1 | %define SYS_mmap 9 |
此时,我们就能为线程分配栈空间(或者准确说是和栈大小相同的内存缓冲区)了。
生成线程
生成线程非常简单,因为它甚至不涉及指令分支!只需往系统调用 clone() 中传入两个参数即可:clone() 的标记以及指向新线程栈的指针。注意,和其他诸多系统调用一样,glibc 包装的函数,其参数顺序与原始系统调用有所不同。总之,包括我们使用的标记在内,它接收两个参数。
1 | long sys_clone(unsigned long flags, void *child_stack); |
我们用于生成线程的函数有如下 C 原型。它接收一个函数指针,而后在线程中执行该函数。
1 | long thread_create(void (*)(void)); |
根据 ABI,函数指针参数会通过寄存器 rdi 传给 thread_create 函数。首先,我们将其安全地保存(push)在栈中,并调用 stack_create()。最后,当函数返回时,线程栈的底部地址会保存在寄存器 rax 当中。
1 | thread_create: |
系统调用 clone() 的第二个参数指向线程栈的顶部地址(具体来说,是线程栈顶部上方页帧的地址)。在代码中,我们通过 lea 指令来计算:读取有效地址(load effective address)。尽管有花括号,但它并不会真的去读取目标内存地址中的内容,而是将该地址保存在目标寄存器(rsi)当中。在代码中,我回退 8 字节的原因是我希望在下一条指令中,把线程函数的指针放在栈顶端。这样做的原因稍后即晓。

注意,函数指针先前被压栈。此处我们将其弹栈并写入当前线程栈空间保留的空间中。
如你所见,使用系统调用 clone() 创建线程时使用了不少标记。这是因为,在默认情况下,大多数东西新的进程都不与原进程共享。你可在 clone(2) 的手册页上找到这些标记的详细含义。
CLONE_THREAD:将子进程放在与父进程相同的线程组内。
CLONE_VM:子进程与父进程在同一虚拟内存空间内运行。
CLONE_PARENT:新的进程与当前进程共享父进程。
CLONE_SIGHAND:共享信号处理器。
CLONE_FS,CLONE_FILES,CLONE_IO:共享文件系统信息。
如此,系统会创建新的线程,并且,如 fork() 一样,syscall 会在两个线程的同一指令处返回。两个线程中,所有的寄存器的值完全相同;但在新线程中 rax 的值是 0,并且在新线程中 rsp 的值与 rsi 的值相等(指向新的线程的栈的指针)。
最酷的地方来了,我们来看看为什么不需要指令分支;即,为什么我们没有必要检查 rax 的值,来确定是原始线程(返回到调用者)还是新线程(跳转到线程函数)?注意新线程的栈顶部保存着指向线程函数的指针:当函数在新线程返回时,执行序列会跳转到线程函数,且线程栈是空的。而原始线程则会使用原始线程的栈,返回调用者。
函数 thread_create() 的返回值是新线程的 PID,本质上就是线程对象(例如 pthread_t)。
清理并退出线程
由于线程函数没有逻辑上的调用者,所以它不能有返回(ret 指令);否则,将导致执行序列脱离线程栈而引发段错误并使程序停止运行。还记得线程其实只是进程吗?它们必须使用系统调用 exit() 来结束运行。在线程中执行系统调用 exit() 不会退出其他线程。
1 | %define SYS_exit 60 |
在退出前,应当使用系统调用 munmap() 释放线程栈,以防有资源泄漏。主线程中等价于 pthread_join() 的系统调用是 wait4()。
后续
若你觉得本文有趣,别忘了查看文章开头处的完整示例之链接。有能力产生线程之后,我们就有机会探索并实验 x86 的同步原语了;例如 lock 前缀的各种锁、xadd 以及诸如 compare-and-exchange(cmpxchg)之类的原子操作。这些内容将在后续文章中讨论。


