这是 2016 年 6 月和百度的技术专家交流的一些经验总结。近期翻出来,记录在这里。
名词解释
- AC:高级搜索(AS 拆出来的),类似于 tuner 上移后的 merger
- DX:存储正排相关的内容,最简单的是存储每个 url 的所有文字内容,然后可以存储各种离线 parse 出来的内容(包括各种段落、命名实体等信息)
- GBRank:可以认为是 GBDT 的同义词
- BS:基于倒排索引的分布式索引的基础检索,类似于 qsrchd 或者 leaf
百度的在线 ranking 相关架构
基本如图。这个应该是表意的,不是完全和实际情况对应的。
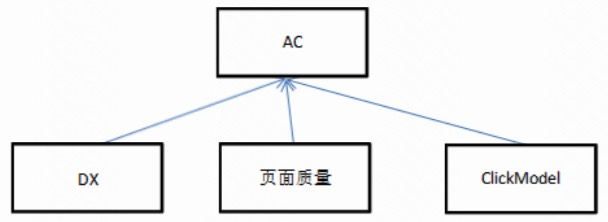
重点说明:
DX - 正排库,对前 300 条结果进行精细正排计算,会重新计算 proximity。这个模块我们当前(2016)是缺失的,我们只有前 100 条结果的title。对方描述里这个模块是非常重要的,是百度 12 年相关性提升最大的项目。
百度的基本流程应该是 BS(qsrchd/leaf)返回结果,merge 后对前 300 条在 DX 重新排序,返回给 AC,AC 继续重新排序,然后返回。
DX 和 AC 各有一个 GBRank 模型来负责排序。
百度 LTR 的发展历程
第一阶段:线性模型
特征的线性拟合:$Y = \sum_{i}\omega_if_i$。
效果:和手写规则基本打平。
好处:基本验证机器学习是可行的,同时,可以得到每个特征有多大作用,即每个特征的 weight,这个 weight 的概念对于理解机器学习有非常大的作用,在后面用非线性模型时,他们依然找到一种计算特征weight的方法,这个方法在debug中也起到很大的作用。
第二阶段:GBRank
这个和我们用的lambdaMart基本类似。
- 标注量:DX 的 GBRank 当标注 query 上升到 7--8w 量级时,有明显提升,对比目前我们的标注量是不到 4w。
- 特征数量:100 左右,比我们少。他们每个特征都做的很细,都有可解释的物理意义,大部分特征会有相应的评测。相反我们有 180 个特征,但是大部分都是围绕点击来做的,同时特征可解释性差,没有单独评测。
- debug 平台:强大的 debug 平台,可以计算每个特征的 weight,在树模型里,对方描述的计算 weight 的方法是在给定的数据集上,固定其他的特征,观察目标特征的变化导致的预测值的变化,用这个变化来计算 weight 的权重。对于具体的 badcase,如果是由于这个 case 在某些特征上不合理,预期 debug 平台是能够发现,所以通过 badcase + debug 平台,能够逐步地改进特征。
- 控制diff,当新加特征时,diff率太大的问题。对方的描述中也提到尝试过 continue train。但是他们最后使用的是bagging的方法来提升模型的稳定性,这个思路我们之前没有想到过,可以借鉴。
第三阶段:深度学习
基本思路和我们目前做的是一样的,但是各种细节还是不一样
- 使用长尾 query 的点击与未点击的数据作为训练数据,他们并没有观察过数据的准确率,但估计还行。相反地,我们用各种方法得到的数据准确率偏低,这个可以在多尝试一些方法。
- 大数据量,100 亿规模,与之对比的是我们只有 1 亿的规模。
- 模型简单,基本上只有一个隐层。
- 多机并行版本,百度 IDL 提供的平台。
- 将深度学习得到的语义相似度作为模型加入到 BRank 里。
问答环节
Q: 百度如何评测
A: 测试集 ndcg + 人工 side by side + 线上小流量实验
Q:DX 的作用
A:DX 提供的正排对于计算 proximity,term 紧密度非常重要,是必不可少的一个模块,并且为后续的一些质量改进可能也提供了基础,对长尾 query 的提升非常大
Q:DX 具体存了什么
A:url 的正排,同时包括 entity/anchor 等,提到分域存储(这个回答貌似不是很全面)
Q:GBRank 如何控制 diff
A:用 bagging 来提升模型稳定性,可以是几个 bagging 的 GBRank,也可以是 GBRank 里面每棵树用 bagging 的方法来生成多个树。Bagging 的 GBDT 已经有人做过了,但是效果和非 bagging 的差不多,但是之前没有人从模型稳定性来看这个问题,从稳定性的角度来看,bagging 就比较重要了。
Q:ltr 的标注规模
A:DX 上升到 7--8w 时效果提升比较大,百度的整体标注规模在几十万 query 级别。每个 query 标注了 20 条。
Q:ltr 标注 query 是怎么选取的
A: 随机,偏向长尾,40%是长尾的。还说看长尾是怎样定义,貌似听见一个搜索次数小于 10 次。
Q:是否采用 active learning 来选取标注集
A: 没有,但是后来在 spam 的机器学习上有采用,因为 spam 的样本少。
Q:百度的标注人力是怎样的
A:全公司的标注是外包的,只需要在平台提交标注任务就可以了
Q:新特征的开发过程是怎样的,是否需要先经过评测,还是直接放到 GBRank 里,通过 debug 来发现特征是否符合预期
A: 新特征一般来讲还是要先经过评测,确保和 label 有一定的相关性
Q:一些需要组合的特征,是否直接加入模型
A:从理论上来讲,直接加入,期望模型学习出来各种组合是可以的,但百度不是这样干的,如果你觉得一些特征需要组合,最好手动组合,把组合后的特征加入到模型
Q:特征的 weight 是如何计算的
A:类似于算导数的方法,上面已经大概说过了。
Q:LTR 的工作方向,模型为主还是特征为主
A:经历不同时期,一开始模型为主,后面加入 DNN 后,特征变的很大,很难做,当然这些特征也是 LTR 团队做。LTR 团队一开始 4 个人,后面发展到接近 20 人。
Q:新特征的上线方式
A:如果另外一个团队升级了一个特征,一般来讲不重新训练,直接上线。如果是新加了特征,ltr 团队会负责重新训练。如果同时加了多个特征,也是 ltr 团队负责重新训练上线
Q:GBRank 上面是否还有 ranksvm
A: 没有
Q:DNN 的并行化方式
A:用的 IDL 的平台,100 多台机器?100 亿的数据规模, 一开始模型比较简单,经过 4--5 个月做出来后,效果非常好。后面也逐渐尝试 cnn,rnn 等
Q:目前我们 1 亿的数据,有啥建议
A:先把数据加到 10 亿,看看效果。他们在 1 亿的时候效果也不明显。可以把 1kw/5kw 数据时的结果拿来观察
Q:ltr 标注量多少比较合适
A:DX在标注到 7--8w 时有比较大的突破。 这个数据提到好几次,可能他们的实际情况确实是数据量提升到 7--8w 时产生了一个质变。
Q:DX 也是 GBRank
A:是,DX 也是用 GBRank 来排序
Q:AC 还有多少基于规则的排序
A:基本没有了,都被替换了,但是 AC 的上游 US 还有一些规则,例如合并 onebox 等
Q:百度结果里经常靠百度知道顶着,大搜索是否对百度知道有特殊处理,例如单字检索等
A:没有对百度知道特殊处理。但是百度知道是一个垂搜, US会请求。同时百度知道有很多站内的权重数据,可能做的比较好
Q:DNN 出来的值是作为特征加入到 GBRank 里的吗?
A:是的
Q:LTR 技术的发展过程
A:先是把 rank 的 LTR 做好,站住脚,然会向外输出技术,例如泛时效性 query 的识别,省略与 termweight、spam 等。
Q:DNN 的关键
A:数据量,必须上大数据量。与 msra 的 gaojianhong 交流是,对于 msra 只用了 1 亿的数据量很鄙视
总结
- LTR 使用的特征非常谨慎:对特征做了很多特征工程,尽量让每个特征有意义。
- DX 起到关键作用,DX 在长尾 query 的基础相关性上起到决定性作用,提供了很多特征。
- GBRank 的 debug 平台非常重要,必不可少。
- DNN 必须上大数据量。


