Python 是一个很实用的脚本语言,学习 Python 无疑需要辅以大量的练习,才能把自己所学运用到实践中去。PythonChallenge 是国外的一款闯关游戏,在挑战关卡的同时学习如何运用 Python 解决问题。
第〇关
http://www.pythonchallenge.com/pc/def/0.html

图片提示计算 2 的 38 次幂方的值。在 Python 解释器中输入
1 | 2**38 |
即可得到答案 274877906944L. 这里最后的 L 表示这是一个长整形的数字。将 274877906944 填入页面地址进入下一关。
第一关
地址跳转到 http://www.pythonchallenge.com/pc/def/map.html, 继续我们的挑战游戏。

图片提示将 K 对应到 M, O 对应到 Q, E 对应到 G. 这是古典密码学典型的移位密码,位移值为 2.
算法
- 建立移位映射关系;
- 读入一个字符;
- 查找映射表;
- 根据映射关系输出一个字符;
- 返回步骤 2, 直至字串末尾。
映射关系可以有多种方法可以建立,可以做一个类似 Python 内建的 dict 类型的 key-value 对应,也可基于 ASCII 码表做数值上的处理。
string 模块有 maketrans 函数,它接收两个等长的字符串,建立从第一个参数到第二个参数逐字符的对应关系,而后用 translate 函数将一个字符串根据这种对应关系转换,返回结果。
string.ascii_lowercase 将返回顺序排放的 26 个小写英文字母。我们可以用切片来得到映射表。
1 | import string |
得到结果:i hope you didnt translate it by hand. thats what computers are for. doing it in by hand is inefficient and that's why this text is so long. using string.maketrans() is recommended. now apply on the url.
内容提示我们,将位移密码作用在当前的 URL 上,即作用在 map 上。得到结果 ocr, 填入地址栏,进入下一关。
第二关
http://www.pythonchallenge.com/pc/def/ocr.html
页面提示说,要在网页源代码中寻找答案。打开源代码后发现有 HTML 注释说要寻找下面一堆乱码中罕见的字符。(我把需要测试的文件,保存在了这里。)
算法
- 建立一个字典,key 是字符,value 是字符出现的次数;
- 读入一个字符;
- 如果该字符已存在字典中,则对应的值加一;若不存在,则新建一个字典条目,设定值为一;
- 返回步骤 2, 直至字串末尾。
- 计算
字符平均出现次数 = 字符总数 / 字典长度; - 遍历字典,输出所有值小于
字符平均出现次数的字符。
算法如果正确,则所谓的「罕见字符」都将被输出。但是有一个问题,Python 中的字典是无序的,按照算法运行,则输出的字符顺序是不可预知的(因为输入的文本不可预知)。我们需要一个「按照输入顺序排序的字典」。所幸,Python 的 collections 模块为我们提供了 OrderedDict 类型。
1 | import collections |
得到结果 equality, 输入地址栏,进入下一关。
第三关
http://www.pythonchallenge.com/pc/def/equality.html
网站提示说:One small letter, surrounded by EXACTLY three big bodyguards on each of its sides.
也就是说,需要找出所有 xXXXxXXXx 类型的结构,取中间那个小写的 x 出来。注意问题关键在于「恰好」二字,意味着不多不少都只能是三个字母,因此我们每次对比,都必须考虑前后一共九个字母。另外,实际上,前后的两个字符,不一定是字母,也可以是特殊符号。比如 #ABCdEFG* 也是满足要求的。(我把需要测试的文件,保存在了这里。)
算法
- 读入一个字符;
- 如果该字符不是小写字母,返回 1; 如果该字符是小写字母,去到 3;
- 检查它的前后各四个字符,是否满足条件,若满足,则记录该字母;
- 检查是否到达字符串尾,若是,则停止;若否,则返回步骤 1.
最简单的方法,是使用 re 模块的正则表达式功能,其中的 findall 函数能够直接完成任务。
1 | import re |
当然,也可以直接控制。
1 | puzzle = ''.join([line.rstrip() for line in open('lv3.txt')]) |
得到结果为 linkedlist, 输入地址栏则进入下一关。
第四关
http://www.pythonchallenge.com/pc/def/linkedlist.html
点进去之后,提示要把后缀改成 php, 改过之后打开一幅图片,点击图片提示说:
and the next nothing is 44827
把地址栏改成 44827 之后,有出现类似提示。于是我们知道这样类似的循环估计得要进行几百次了,手工一次次改肯定不现实,上 Python 吧。
手工点几次之后会发现,地址和页面内容是有规律的。页面内容中的 nothing is 后面接的数字,总是跟在地址栏的 nothing= 后面。利用这个规律,代码如下。
1 | import urllib, re |
执行之后,会有一次停顿,需要你对某个数字除二然后重新开始,代码类似,这里就不想说了。
得到结果 peak.html, 进入下一关。
第五关
http://www.pythonchallenge.com/pc/def/peak.html
进去之后发发现一幅图,图上有一座小山;图的下方有一行提示,让我们「读出它」。结合页面标题 peak hell, 知道它和 Python 的一个模块 pickle 音近。pickle 提供了两组函数,每组函数里面有各有两个互逆的操作。其中一组针对文件对象操作,另一组操作的则是 Python 的变量。针对文件对象的两个函数是 dump 和 load, 针对 Python 变量的则是 dumps 和 loads. 其中 dump(s) 将数据以某种方式存入文件(变量),而 load(s) 则将 dump(s) 存入的内容读出。
pickle 模块还有一个用 C 语言实现的版本,称为 cPickle。相对原本的 pickle 版本,cPickle 执行效率更高一些,但是无法被继承。
既然我们知道需要用 pickle 了,就要去找一个对象。按照这个小游戏的风格,右键查看源码,发现 http://www.pythonchallenge.com/pc/def/banner.p 这个文件。我们用 urllib 把它读下来,然后用 pickle 处理。
1 | import urllib |
我们会发现,pwc 变量是一个复杂的结构。首先它是一个 list, 这个最外层的 list 里的数据是更小一层的 list; 小一层的 list 里的数据则是一个个 pairs. 如果你用过 *nix 系统,可能会对这种数据结构有些熟悉。仔细观察你会发现,每个小 list 里 pairs 里的数字之和正好都是 95, 而每个 pair 里都有一个长度为 1 的字符串。这意味着,整个大的 list 是一个文本块;每一个小的 list 是一行;每一个 pair 是重复若干次相应的字符。我们来输出它。
1 | print '\n'.join([''.join([p[0] * p[1] for p in row]) for row in pwc]) |
我们会发现如图所示的内容。

其中显示的内容 channel, 正是我们的过关提示。
第六关
http://www.pythonchallenge.com/pc/def/channel.html
打开网页后,出现的是一幅牛仔裤拉链的图。拉链的英文是 zip. 和 Python 相关的话,zip 可以是我们熟悉的 .zip 格式,也可以是 Python 内建的函数。考虑没有更多的提示信息,我们试试 chennel.zip.
1 | import urllib, StringIO, zipfile |
WOW! 好多…… len 看一下,居然有 910 个文件在里面,太可怕了。
等等!在刚才 namelist 的最后,有一个 readme.txt! 抓住救命稻草了有木有啊!
1 | print unzipped.read('readme.txt') |
出现提示说,从 90052 开始搞起。难道说又要重复第四关那种情况?
1 | import urllib, re, StringIO, zipfile |
提示说:Collect the comments. 囧,原来遍历一遍还不够啊。再次修改代码,去拿 txt 的注释去。
1 | import urllib, re, StringIO, zipfile |
我们得到:
HOCKEY 就是我们的过关代码吗?太天真了!
进入 http://www.pythonchallenge.com/pc/def/hockey.html 之后得到提示「it's in the air. look at the letters.」 提示说,空气里有这东西,并且让我们看看刚才那图案。我们发现 HOCKEY 分别由 oxygen 组成。看来 oxygen 才是下一级的入口!
第七关
http://www.pythonchallenge.com/pc/def/oxygen.html
打开来只有一幅图片:

额,这是啥?信息隐藏在中间那个灰度条中嘛?好吧我们来处理图片好了。Python Imaging Library 提供了 Image 模块,可以用来处理图片。
我们需要先下载安装。Image 模块提供了 getpixel 来获得某个像素点上的 RGBA 值(RGB 是颜色,A 是不透明度)。对于灰度图片来说,RGB 三者的值应该相等,我们可以据此提出所需的灰度部分,然后进行判断。
1 | import urllib, Image, StringIO |
我们发现最终的输出中,大部分字母都重复了 7 次。这说明图片中一个灰度小块的宽度是 7 个像素。我们可以取其中的一行(比如 47 行),然后将步长设置为 7:
1 | print ''.join([chr(imageWeb.getpixel((j, 47))[0]) for j in range(0,width,8)]) |
这样就能得到最终的结果了:"smart guy, you made it. the next level is [105, 110, 116, 101, 103, 114, 105, 116, 121]". 再次转换这个结果:
1 | print ''.join([chr(j) for j in [105, 110, 116, 101, 103, 114, 105, 116, 121]]) |
得到:integrity. 这就是我们的通关密码!
第八关
http://www.pythonchallenge.com/pc/def/integrity.html
点开之后发现,有一幅图片,上面画着一只蜜蜂;图片下面是提示「隐藏的链接在哪里」。鼠标点击蜜蜂会进入到下一关的页面——不过没这么简单,要输入密码的。
输入密码提示单词 inflate, 意为膨胀。
至此,线索已经断了,于是回到第八关页面,右键查看网页源代码,发现注释部分有
1 | un: 'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084' |
BZh9 是 bz2 压缩的著名起始字符。结合 inflate, 不难联想到,我们的任务是通过 un 和 pw 后面的内容,用 bz2 解压得到 username 和 password.
1 | un = 'BZh91AY&SYA\xaf\x82\r\x00\x00\x01\x01\x80\x02\xc0\x02\x00 \x00!\x9ah3M\x07<]\xc9\x14\xe1BA\x06\xbe\x084' |
得到结果 huge 和 file, 进入下一关,结束战斗。
第九关
http://www.pythonchallenge.com/pc/return/good.html
打开网页后见到图片:

网页标题提示我们,连点成线。可是图片中的黑色方块连起来啥也不是。打开网页源码发现里面有提示 first + second = ?, 以及两个很长的 list. 莫非是要我们将这两个 list 当作是坐标来连线?用 PIL 的 ImageDraw 模块可以搞定。
1 | import Image, ImageDraw |
我们得到的结果是:

这是一头公牛——想想 NBA 里的公牛队——答案是 bull!
第十关
http://www.pythonchallenge.com/pc/return/bull.html
图片提示是一头牛,要求计算 len(a[30]). 标题提示说「你看啥呢」,看样子又是故技重施。我们点击图片上的牛,进入 http://www.pythonchallenge.com/pc/return/sequence.txt, 发现了一个不完整的数字序列:a = [1, 11, 21, 1211, 111221,. 所以我们的任务是找这个序列的规律,然后找到它的第 30 项然后返回长度。
乍一看,这是什么情况,小学奥数嘛?把序列放 Google 里搜索,发现这是一个叫做「外观序列」的东西,参见维基百科。意思是,序列的后一项是对前一项的描述。比如 11 表示「一个 1」,也就是前一项的 1;又比如 111221 表示「一个 1, 一个 2, 两个 1」,也就是前一项的 1211.
1 | import re |
这里写了一个用正则表达式处理的代码。其中的 (\d)(\1*) 表示匹配任意数字的连续,也就是匹配 111, 22 这样的序列。这样我们就能得到答案了。返回 5808.
第十一关
http://www.pythonchallenge.com/pc/return/5808.html
打开页面后,是一幅图片:

唯一的提示是页面标题的"odd even"(奇偶)。
仔细查看图片,会发现图片的「颗粒化」现象很严重——几乎每一个像素点的旁边,都有黑色的颗粒。再结合「奇偶」这个提示,我们有理由猜想,图片是两张图拼接起来的,像素坐标的奇偶分别对应着一张图。
现在我们可以对图片的横纵坐标,分别取出奇数序列和偶数序列,然后生成四幅图片:
- x-odd, y-odd
- x-odd, y-even
- x-even, y-even
- x-even, y-odd
代码:
1 | import Image |
这样我们生成了四幅图片:
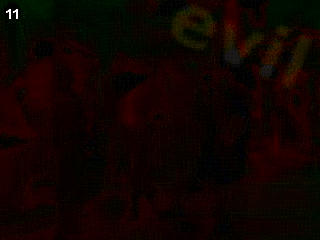
可以看到图中的 evil 字样。这就是下一关的钥匙。
第十二关
http://www.pythonchallenge.com/pc/return/evil.html
打开网页后发现只有一张图片,看图片那样子似乎又要处理?网页标题提示 dealing evil, 即处理 evil. 打开网页源代码,没啥特别的信息。
等等!
图片的名字是 http://www.pythonchallenge.com/pc/return/evil1.jpg, 那么有 evil1 的话,会不会还有 evil2, evil3, evil4 ... 呢?
在地址栏中把地址改成 evil2.jpg, 得到一张图片,上面歪歪曲曲地写着
not .jpg .gfx
于是把 evil2.jpg 改成 evil2.gfx, 得到一个十六进制文件。继续改 evil3.jpg, 得到图片说
no more evils...
嗯,提示说没有恶魔(复数)了,那么就是还有一个?继续改 evil4.jpg, 页面提示
Bert is evil! go back!
答案和 bert 有关嘛?进入地址 http://www.pythonchallenge.com/pc/return/bert.html, 页面提示说
Yes! Bert is evil!
看来答案果然和 bert 有关。Google 搜索发现 BERT 是 Bit Error Ratio Test 的缩写(比特误码率测试)。我们先前得到的 gfx 文件是一个十六进制的文件(换言之,可以很简单地转换成二进制文件),这就和所谓的比特误码率很相关了。所以难道信息隐藏在 BERT 里面吗?Google 许久未果,没发现和题目有什么有什么关系。看样子又要卡几天了。


