传统的搜索引擎排序(Ranking)问题,通常会涉及到很多的排序策略。这些策略根据不同的特征,在不同的适用范围中起作用。因此,一个传统的排序算法,至少涉及到两方面的内容:策略的制定,以及不同策略的组合。策略的组合需要考虑策略分析适用的特征,以及相应策略的适用情况。根据这些内容,通过人工或者半机器半人工的方式组合起来,才能组成一个可堪使用的排序算法。
和自然语言处理中遇到的情况一样,随着数据量的增加,使用人工的方式做策略的组合,会变得越来越困难。因此,将机器学习引入搜索引擎排序问题,也就是相当自然的事情了。在排序问题中使用的机器学习算法,被称为 Learning to Rank (LTR) 算法,或者 Machine-Learning Rank (MLR) 算法。
LTR 算法通常有三种手段,分别是:Pointwise、Pairwise 和 Listwise。Pointwise 和 Pairwise 类型的 LTR 算法,将排序问题转化为回归、分类或者有序分类问题。Listwise 类型的 LTR 算法则另辟蹊径,将用户查询(Query)所得的结果作为整体,作为训练用的实例(Instance)。
LambdaMART 是一种 Listwise 类型的 LTR 算法,它基于 LambdaRank 算法和 MART (Multiple Additive Regression Tree) 算法,将搜索引擎结果排序问题转化为回归决策树问题。MART 实际就是梯度提升决策树(GBDT, Gradient Boosting Decision Tree)算法。GBDT 的核心思想是在不断的迭代中,新一轮迭代产生的回归决策树模型拟合损失函数的梯度,最终将所有的回归决策树叠加得到最终的模型。LambdaMART 使用一个特殊的 Lambda 值来代替上述梯度,也就是将 LambdaRank 算法与 MART 算法加和起来。考虑到 LambdaRank 是基于 RankNet 算法的,所以在搞清楚 LambdaMART 算法之前,我们首先需要了解 MART、RankNet 和 LambdaRank 是怎么回事。
MART 算法
MART,即多重增量回归树(Multiple Additive Regression Tree)有许多名字:
- MART - 多重增量回归树(Multiple Additive Regression Tree)
- GBDT - 梯度渐进决策树(Gradient Boosting Decision Tree)
- GBRT - 梯度渐进回归树(Gradient Boosting Regression Tree)
- TreeNet - 决策树网络(Tree Net)
这些名字的含义都一样,都是一个意思。
从这些名字,我们可以看出 MART 的一些特征:
- 使用决策树来预测结果;
- 用到的决策树有很多个;
- 每个树都比之前的树改进一点点,逐渐回归、拟合到真实结果。
实际上,这三点就是 Boosting 思想的精髓了。Boosting 思想源自 Kearns 和 Valiant 的提问,并最终从 Robert Schapire 在 1990 年的论文 The Strength of Weak Learnablity 中对上述问题明确的回答发展起来。
Boosting(渐进)思想
Boosting 思想,尝试通过不断迭代弱模型(Weak Learner),通过叠加弱模型的方式,渐进地逼近真实情况,起到足以预测真实值的强模型的作用。显而易见,Boosting 思想至少需要解决两个问题:
- 如何保证每一次迭代都对解决问题有所帮助,或者说如何确定迭代步骤中拟合的方向?
- 如何将每一次迭代产生的弱模型有效地叠加起来?
下面,我们通过 AdaBoost(Adaptive Boosting,自适应渐进法)来回答这两个问题。
AdaBoost
AdaBoost 是 Yoav Freund 和 Robert Schapire 提出的机器学习算法。两人因为该算法获得了 2003 年的哥德尔奖。
AdaBoost 是一种用于分类的算法,它的运行过程大致可以理解如下:
- 制作一个弱分类器(实际是一个决策树),去拟合实际情况,我们将它记录为
WL1。 - 运行
WL1,记录分类错误的那些样本。接下来,赋予这些被错误分类的样本比较高的权重,进行第二次拟合,得到新的弱分类器WL2。 - 依次运行
WL1-WL2,记录分类错误的那些样本。接下来,赋予这些被错误分类的样本比较高的权重,进行第三次拟合,得到新的弱分类器WL3。 - 依次运行
WL1-WL2-WL3,如此迭代……

上图来自 Pattern Recognition and Machine Learning 一书的 660 页,讲述的是运用 Boosting 思想进行分类的过程。
蓝色和红色的圆圈,代表两类样本,圆圈的大小代表当前该点的权重;绿色的线条代表训练既得分类器模型;虚线表示当前训练新增的分类器模型。
可以看到,在不断的迭代过程中,每一次迭代,分类器都会关注之前区分错误的那些样本点,进行有针对性的处理。因此,在进行到 150 次迭代之后($m = 150$),最终叠加起来的模型已经非常细致,足够将红蓝两种类别细致地区分开来了。
整个过程,用数学符号表达如下(PRML Page 658):

在这里:
- $w^{(k)}_n$ 表示一个 $n$ 元向量,向量中的每一个元素都对应训练集中的一个样本点;向量中元素的值,就是所对应样本点在第 $k$ 次迭代中的权重。
- $y_{k}(\mathbf{x})$ 是根据上述权重计算出来的第 $k$ 次迭代的模型。
- $\alpha_{k}$ 是第 $k$ 次迭代的模型的权重。
- $Y_M(\mathbf{x})$ 是根据上述 $M$ 个弱分类器加权求和得到的最终分类器。
最开始的时候,每个样本点的权重都一致。随着算法不断迭代,被错误分类的样本,权重不断加强,与此同时被正确分类的样本,权重不断减弱。可以想象,越往后,算法越关注那些容易被分错的样本点,从而最终解决整个问题。
现在,我们至少可以从 AdaBoost 的角度回答上一小节的两个问题了:
- AdaBoost 通过调整样本的权值,来确定下一轮迭代中弱模型的拟合方向:提升分类错误的样本的权值,降低分类正确的样本的权值。
- AdaBoost 用一个「加法模型」,将每一轮迭代得到的弱模型组合叠加起来,得到一个有效的强模型。
MART 的数学原理
MART 是一种 Boosting 思想下的算法框架,它的目标是寻找强模型 $f(x)$ 满足:
$$\hat f(x) = \text{arg min}_{f(x)} E\Bigl[L\bigl(y, f(x)\bigr) \big| x\Bigr]$$
和 AdaBoost 一样,训练之后的 MART 模型也是一个加法模型,形式如下:$$ \label{eq:MART-result} \hat f(x) = \hat f_M(x) = \sum_{m = 1}^M f_m(x) $$
这里:
- $\hat f = \hat f_M: \mathbb{R}^d \mapsto \mathbb{R}$ 是模型的目标函数;
- $x \in \mathbb{R}^d$ 是样本点,它包含 $d$ 个特征的值;
- $\hat f(x) \in \mathbb{R}$ 是预测值;
- $M$ 是训练过程中迭代的次数,也就是模型中回归决策树的数量;
- $f_m: \mathbb{R}^d \mapsto \mathbb{R}$ 是模型训练过程中得到的弱模型(也就是回归决策树)。
那么,关于 MART 的 Boosting,我们还剩下一个回答,即:如何保证每一次迭代都对解决问题有所帮助,或者说如何确定迭代步骤中拟合的方向。接下来的分析,我们就来解决这个问题。
假设我们已经迭代了 $m$ 次,得到了 $m$ 颗决策树。我们将这 $m$ 颗决策树的和记作 $\hat f_m(x) = \sum_{i = 1}^m f_i(x)$,于是,第 $m + 1$ 轮拟合的目标
\begin{equation} \delta \hat f_{m + 1} = \hat f_{m + 1} - \hat f_m = f_{m + 1} \end{equation}
现在我们要求这个 $\delta \hat f_{m + 1}$。我们引入损失函数
$$ L = L\bigl((x, y), f\bigr) = L \bigl(y, f(x) \big| x\bigr) $$
来描述预测函数 $f$ 的预测结果 $y^{*} = f(x)$ 与真实值 $y$ 的差距。那么,我们的目的是要在进行第 $m + 1$ 轮拟合之后,预测值与真实情况的差距会减小,即
$$ \delta L_{m + 1} = L\bigl((x, y), \hat f_{m + 1}\bigr) - L\bigl((x, y), \hat f_{m}\bigr) \lt 0 $$
考虑到
$$ \delta L_{m + 1} \approx \frac{\partial L\bigl((x, y), \hat f_m\bigr)}{\partial \hat f_m}\cdot \delta \hat f_{m + 1}, $$
若取
\begin{equation} \label{eq:gradient} \delta \hat f_{m + 1} = -g_{im} = -\frac{\partial L\bigl((x, y), \hat f_m\bigr)}{\partial \hat f_m}, \end{equation}
则必有 $\delta L_{m + 1} \lt 0$。因此,这个 $\delta \hat f_{m + 1}$ 就是 $f_{m + 1}$ 拟合的目标;也就是说,$f_{m + 1}$ 要拟合这样一个训练集:
$$ \Biggl\{i = 1, 2, \ldots, N \Bigg\vert \biggl(x_i, -\frac{\partial L\bigl((x_i, y_i), \hat f_m(x_i)\bigr)}{\partial \hat f_m(x_i)}\biggr)\Biggr\} $$
式 \ref{eq:gradient} 描述的正是损失函数(泛函) $L$ 的梯度。亦即,循环迭代中,模型每次拟合的目标都是损失函数的梯度。这就是算法被称为「梯度渐进」的原因。
决策树实际上将样本空间划分成了若干区域,并对每个划分区域赋上预测值。假设 $f_m$ 划分而成的区域是 $R_m$,预测值则是 $\gamma_m$。那么,我们有$$ f_m(x) = h_m(x; R_m, \gamma_m), $$
也就是$$ \hat{f}(x) = \sum_{m=1}^{M}f_m(x) = \sum_{m=1}^{M}h_m(x; R_m, \gamma_m). $$
那么,MART 的每一步也就是要解优化问题:\begin{equation} \label{eq:argmin} h_m(x; R_m, \gamma_m) = \text{arg min}_{R, \gamma}\sum_{i = 1}^{N} \bigl(-g_{im} - F(x_i;R,\gamma)\bigr)^2,\tag{$ \star $} \end{equation}
其中 $F$ 是一棵回归决策树。
现在我们引入一个非常小的正数 $ \eta $,称为「学习度」或者「收缩系数」。如果,我们在每轮迭代中的预测结果前,乘上这么一个学习度;亦即我们将第 $m + 1$ 轮拟合的目标,从 $-g_{im}$ 调整为 $-\eta\cdot g_{im}$。这样一来,我们每次拟合的目标,就变成了损失函数梯度的一部分。由于 $\delta L \lt 0$ 仍然成立,经过多次迭代之后,模型依然可以得到一个很好的结果。但是,与引入学习度之前的情况相比较,每次拟合像是「朝着正确的方向只迈出了一小步」。这种 Shrinkage(缩减),主要是为了防止「过拟合」现象。
小结
MART 是一种 Boosting 思想下的算法框架。它通过加法模型,将每次迭代得到的子模型叠加起来;而每次迭代拟合的对象都是学习率与损失函数梯度的乘积。这两点保证了 MART 是一个正确而有效的算法。
MART 中最重要的思想,就是每次拟合的对象是损失函数的梯度。值得注意的是,在这里,MART 并不对损失函数的形式做具体规定。实际上,损失函数几乎只需要满足可导这一条件就可以了。这一点非常重要,意味着我们可以把任何合理的可导函数安插在 MART 模型中。LambdaMART 就是用一个 $\lambda$ 值代替了损失函数的梯度,将 $\lambda$ 和 MART 结合起来罢了。
Lambda
Lambda 的设计,最早是由 LambdaRank 从 RankNet 继承而来。因此,我们先要从 RankNet 讲起。
RankNet 的创新
Ranking 常见的评价指标都无法求梯度,因此没法直接对评价指标做梯度下降。
RankNet 的创新之处在于,它将不适宜用梯度下降求解的 Ranking 问题,转化为对概率的交叉熵损失函数的优化问题,从而适用梯度下降方法。
RankNet 的终极目标是得到一个带参的算分函数:
$$s = f(x; w).$$
于是,根据这个算分函数,我们可以计算文档 $x_i$ 和 $x_j$ 的得分 $s_i$ 和 $s_j$
$$s_i = f(x_i; w)\quad s_j = f(x_j; w),$$
然后根据得分计算二者的偏序概率
$$P_{ij} = P(x_i \rhd x_j) = \frac{\exp\bigl(\sigma\cdot(s_i - s_j)\bigr)}{1 + \exp\bigl(\sigma\cdot(s_i - s_j)\bigr)} = \frac{1}{1 + \exp\bigl(-\sigma\cdot(s_i - s_j)\bigr)},$$
再定义交叉熵为损失函数
$$L_{ij} = -\bar{P}_{ij}\log P_{ij} - (1 - \bar{P}_{ij})\log (1 - P_{ij}) = \frac12 (1 - S_{ij})\sigma\cdot(s_i - s_j) + \log\Bigl\{1 + \exp\bigl(-\sigma\cdot(s_i - s_j)\bigr)\Bigr\},$$
进行梯度下降$$w_k \to w_k - \eta\frac{\partial L}{\partial w_k}.$$
再探梯度
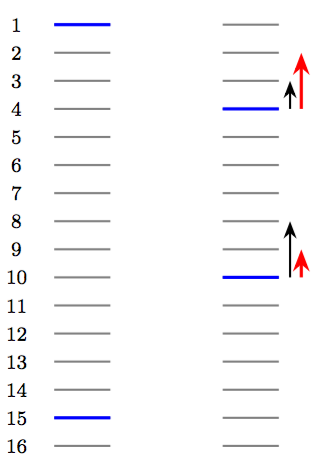
这里每条横线代表一条文档,其中蓝色的表示相关的文档,灰色的则表示不相关的文档。在某次迭代中,RankNet 将文档的顺序从左边调整到了右边。于是我们可以看到:
- RankNet 的梯度下降表现在结果的整体变化中是逆序对的下降:13 → 11
- RankNet 的梯度下降表现在单条结果的变化中,是结果在列表中的移动趋势(图中黑色箭头)
- 我们通常更关注前几条文档的排序情况,因此我们会期待真正的移动趋势如图中红色箭头所示
那么问题就来了:我们能不能直接定义梯度呢?
LambdaRank
现在的情况是这样:
- RankNet 告诉我们如何绕开 NDCG 等无法求导的评价指标得到一个可用的梯度;
- 上一节我们明确了我们需要怎样的梯度;
- 梯度(红色箭头)反应的是某条结果排序变化的趋势和强度;
- 结果排序最终由模型得分 $s$ 确定。
于是,我要扼住 $\frac{\partial L_{ij}}{\partial s_i}$ 的咽喉!
先看看 RankNet 的梯度$$ \frac{\partial L}{\partial w_k} = \sum_{(i, j) \in P}\frac{\partial L_{ij}}{\partial w_k} = \sum_{(i, j) \in P} \frac{\partial L_{ij}}{\partial s_i}\frac{\partial s_i}{\partial w_k} + \frac{\partial L_{ij}}{\partial s_j}\frac{\partial s_j}{\partial w_k}, $$
注意有下面对称性$$ \begin{aligned} \frac{\partial L_{ij}}{\partial s_i} & {} = \frac{\partial \biggl\{\frac12 (1 - S_{ij})\sigma\cdot(s_i - s_j) + \log\Bigl\{1 + \exp\bigl(-\sigma\cdot(s_i - s_j)\bigr)\Bigr\}\biggr\}}{\partial s_i}\\ & {}= \frac12 (1 - S_{ij})\sigma - \frac{\sigma}{1 + \exp\bigl(\sigma\cdot(s_i - s_j)\bigr)} \\ & {}= \sigma\Biggl[\frac12(1 - S_{ij}) - \frac{1}{1 + \exp\bigl(\sigma\cdot(s_i - s_j)\bigr)}\Biggr] \\ & {}= -\frac{\partial L_{ij}}{\partial s_j}. \end{aligned} $$
于是我们定义$$ \lambda_{ij}\mathrel{\stackrel{\mbox{def}}{=}} \frac{\partial L_{ij}}{\partial s_i} = -\frac{\partial L_{ij}}{\partial s_j}, $$
考虑有序对 $(i, j)$,有 $S_{ij} = 1$,于是有简化$$ \lambda_{ij}\mathrel{\stackrel{\mbox{def}}{=}} - \frac{\sigma}{1 + \exp\bigl(\sigma\cdot(s_i - s_j)\bigr)}, $$
在此基础上,考虑评价指标 $Z$(比如 NDCG)的变化$$ \lambda_{ij}\mathrel{\stackrel{\mbox{def}}{=}} - \frac{\sigma}{1 + \exp\bigl(\sigma\cdot(s_i - s_j)\bigr)}\cdot\lvert\Delta Z_{ij}\rvert. $$
对于具体的文档 $x_i$,有$$ \lambda_{i} = \sum_{(i, j) \in P}\lambda_{ij} - \sum_{(j, i) \in P}\lambda_{ij}. $$
也就是说:每条文档移动的方向和趋势取决于其他所有与之 label 不同的文档。
现在回过头来,看看我们做了什么?
- 分析了梯度的物理意义;
- 绕开损失函数,直接定义梯度。
当然,我们可以反推一下 LambdaRank 的损失函数:
$$L_{ij} = \log\Bigl\{1 + \exp\bigl(-\sigma\cdot(s_i - s_j)\bigr)\Bigr\}\cdot\lvert\Delta Z_{ij}\rvert.$$
LambdaMART
现在的情况变成了这样:
- MART 是一个框架,缺一个「梯度」;
- LambdaRank 定义了一个「梯度」。
让他们在一起吧!于是,就有了 LambdaMART。

LambdaMART 的优点
LambdaMART 有很多优点,取一些列举如下:
- 直接求解排序问题,而不是用分类或者回归的方法;
- 可以将 NDCG 之类的不可求导的 IR 指标转换为可导的损失函数,具有明确的物理意义;
- 可以在已有模型的基础上进行 Continue Training;
- 每次迭代选取 gain 最大的特征进行梯度下降,因此可以学到不同特征的组合情况,并体现出特征的重要程度(特征选择);
- 对正例和负例的数量比例不敏感。


