前些天在 Bilibili 上看到一个视频(6 分钟演示 15 种排序算法)。好事者戏称:「在视频中,你能听到:冒泡咕噜声、飞机坠地声、暖瓶灌水声、猴子乱叫声等等」,实在搞笑得很。
C++ 的标准模板库有一个很霸气的解读:「标准模板库里的任意算法、数据结构,你找不到一个实现,在所有的情况下都优于标准模板库的实现;否则,它就应该进入标准模板库」。因此,对于排序问题来说,C++ 里的标准模板库中的 std::sort 可想而知是一个在绝大多数情况下都能达到极限性能的排序算法。
前文介绍的内省式排序算法正是 std::sort 采用的算法。但仅有一个理论上优秀的算法是不够的,std::sort 在内部也有很多技巧和权衡值得细细品味。这篇文章尝试来剖析 std::sort。
侯捷的《STL 源码剖析》选择了 SGI STL 2.91 版本来分析,理由是这个版本在技术层次、源代码组织、源代码可读性等方面的表现都非常好,并且这个版本代码较为稳定。本文也以这个版本为基础进行分析。
std::sort
简便起见,我们分析默认版本的 std::sort,而不讨论传入仿函数 Compare 的版本。
1 | template <class RandomAccessIterator> |
这是一个函数模板,接受两个随机访问迭代器 first 和 last。两个随机访问迭代器构成了待排序的左闭右开区间 [first, last)。注意,这里假设 last 不会先于 first。显然,此时区间的有效性等价于 first != last。
内部的 __introsort_loop 即是上一篇文章介绍的内省式排序的实现。__final_insertion_sort 则是插入排序,参照前文它在几乎有序的情况下效率很高。因此 std::sort 在内省式排序基本完成任务后调用插入排序以提升效率。
__introsort_loop
1 | template <class RandomAccessIterator, class T, class Size> |
这是内省式排序的实现,它接收 4 个参数:前两个参数对应 std::sort 的左闭右开区间,第三个参数利用 Type Traits 获取待排序区间元素的类型,第四个参数则是前文提到的递归深度限制。
__stl_threshold
__stl_threshold 是一个预定义的宏,它对应前文提到的超参数。当左闭右开区间的长度不大于该超参数时,可以认为序列基本有序,于是退出内省式排序,转向插入排序。
if (depth_limit == 0) 与 --depth_limit
这是内省式排序判断快排递归恶化的一步。每次 __introsort_loop 的递归,参数 depth_limit 都会自减一次;当该参数为 0 时,意味着递归深度已经很深,很可能快排掉入了陷阱,因此调用堆排,并退出递归。
1 | template <class RandomAccessIterator, class T, class Compare> |
值得一提的是,在 std::sort 当中,内省式排序的 depth_limit 初始值是 __lg(last - first) * 2,即 $2\log_2{n}$。这与前文的分析是一致的。
递归结构
处理过恶化情况后,理应是正常的快排算法的实现了。快排是一个典型的递归算法,写起来其实很简单:
1 | qsort(first, last): |
这无非是先分割,然后递归分别处理左右子序列。但是 std::sort 里的快排,生生写成了类似这样:
1 | qsort(first, last): |
这里先分割,然后递归处理右子序列,左子序列则通过重新设置 last 的位置交由下一轮循环处理。这种处理方式节省了一半的递归调用开销;在待排序序列非常长的时候,无疑能提高不少效率。可谓「为了效率,无所不用其极」。
pivot 的选择
前文提到,快排掉入陷阱的根本原因是主元选择得不好导致分割没有带来任何新的信息量。具体来说,就是主元选择了序列中最大或最小的元素。
1 | __median(*first, *(first + (last - first) / 2), *(last - 1)) |
为了避免这种情况,std::sort 中的快排,主元选择了首元素、尾元素和中央位置元素三者中的中位数。这样一来,除非这三个元素都是最大值或最小值,不然三者的中位数不会是整个序列的最大值或最小值,从而不容易让快排掉入陷阱。
__unguarded_partition
快排的核心是根据主元对序列进行分割。std::sort 当中使用了 __unguarded_partition 函数进行这一操作。
1 | template <class RandomAccessIterator, class T> |
函数接受 3 个参数,分别是左闭右开区间的迭代器和主元的值。
(1.1) 和 (1.2) 配合,将 first 迭代器后移,指向第一个不小于主元的元素。(2.1) 和 (2.2) 配合,将 last 迭代器前移,指向第一个不大于主元的元素。在 (3) 处的判断,若第一个不小于主元的元素不先序于第一个不大于主元的元素,则说明分割已经完毕,返回第一个不小于主元的元素的位置,即 first 的当前值;否则,在 (4) 处交换 first 和 last 指向元素的值。参考《STL 源码剖析》的图示:
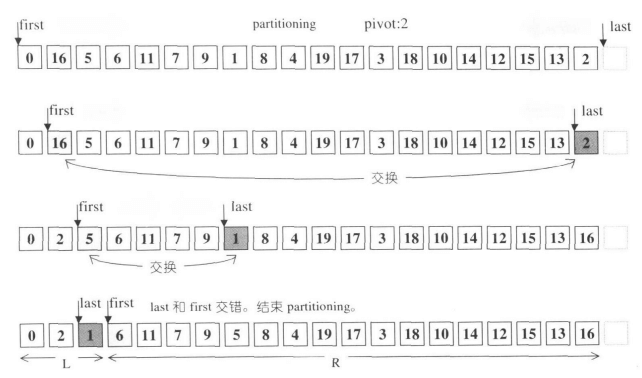
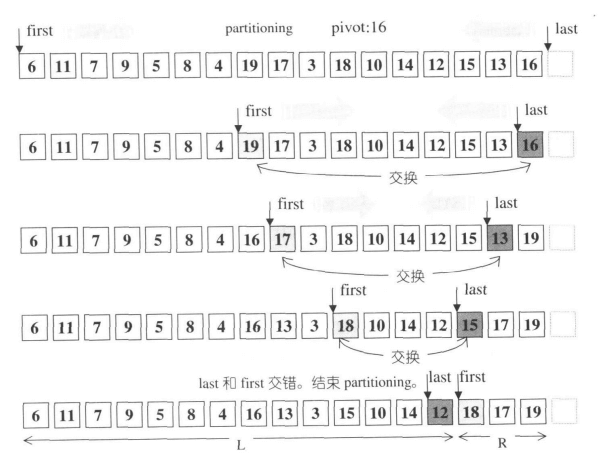
对于该函数有两个地方值得一提:
- 函数没有进行任何边界判断而不会陷入死循环的原因是
pivot是[first, last)内的元素,因此在循环中first和last必然会破坏先序关系(不一定是交错)。避免边界判断,又节省了不少比较开销。 - 不同于标准的 partition 返回主元的分割位置,
__unguarded_partition返回的是第一个不小于主元的元素位置。由于在[first, last)长度足够小时,函数会退出并交由插入排序实现,这种设计并不会影响算法的正确性。
__final_insertion_sort
在 __introsort_loop 将 [first, last) 调整为基本有序后,就会转而进入插入排序。
1 | template <class RandomAccessIterator> |
函数模板内有一个 if 分支。当区间长度较小时,直接调用 __insertion_sort;当区间长度较大时,对前 __stl_threshold 个元素调用 __insertion_sort,而对前 __stl_threshold 个元素之后的元素调用 __unguarded_insertion_sort。有了之前分析 __unguarded_partition 的经验,显然我们能猜到 __unguarded_insertion_sort 一定做了某种优化以提升性能。但我们有几个问题待解决:
__insertion_sort和__unguarded_insertion_sort分别是什么?它们与标准的插入排序有什么区别?各自的适用条件又是什么?- 在区间长度较长时,为什么要将前
__stl_threshold个元素单独处理? - 为什么要对区间长度的大小进行划分?这与
__introsort_loop中while循环的区间长度限制有什么联系?
插入排序的实现
标准的插入排序可以有这样的实现:
1 | template <class RandomAccessIterator> |
代码很简单。(1) 处从 first 之后的元素开始循环,假定 first 已经是排序完成的。(2) 处从目标位置 i 前一个元素向前循环,直到遇到区间头部或者遇到已排序元素小于目标元素时停止;在循环内的 (3) 处依次将大于目标元素的所有元素依次后移。(4) 处将目标元素放在目标位置。
接下来我们首先来看 __unguarded_linear_insert 的代码,它是 __insertion_sort 和 __unguarded_insertion_sort 共同依赖的内部函数。
1 | template <class RandomAccessIterator, class T> |
__unguarded_linear_insert 函数模板的实现如其名称所展现的那样,它在对 next 迭代器的自减中,没有检查 next 迭代器是否向左超越边界。更有甚者,它根本无需输入左边界,而只需输入右边界迭代器和带插入元素的值即可;这也意味着,__unguarded_linear_insert 不是完整的插入排序的实现。事实上,它只完成了原版插入排序中 (2)(3)(4) 的部分功能。
显然,这种情况下,为了保证函数执行的正确性,函数必然有额外的前提假设。此处假设应当是:while 循环会在 next 迭代器向左越界之前停止;这也就是说,在 [first, last) 之间必然存在不大于 value 的元素。因此,为防止越界,在调用该函数模板之前,我们必须要保证这一假设成立。
接下来我们来看内部函数 __linear_insert 的实现。
1 | template <class RandomAccessIterator, class T> |
__linear_insert 函数模板的意图是将 last 所指向的元素插入到正确位置,这里蕴含的前提假设是**[first, last) 区间的元素是已经排好序的**。在这一假设下,若 *last < *first,则毫无疑问,last 指向的元素应当插入在上述区间的最前面,因此有 std::copy_backward;若不满足条件判断,则在 [first, last) 之间必然存在不大于 value 的元素(比如至少 *first 是这样),因此可以调用 __unguarded_linear_insert 来解决问题,而不必担心在 __unguarded_linear_insert 中 next 迭代器向左越界。对于 *last < *first 的情况,__linear_insert 将 last - first - 1 次比较和交换操作变成了一次 std::copy_backward 操作,相当于节省了 last - first - 1 次比较操作。
利用 __linear_insert 可以将 last 指向的元素插入到已排序区间中的正确位置;而这正式标准的插入排序函数中 (2)(3)(4) 处的目的。因此 __insertion_sort 就很好理解了。
1 | template <class RandomAccessIterator> |
接下来我们看 __unguarded_insertion_sort 的实现。
1 | template <class RandomAccessIterator, class T> |
__unguarded_insertion_sort_aux 是一个简单的辅助函数,其目的只是获取模板参数 T,以便正确调用 __unguarded_linear_insert。__unguarded_insertion_sort 没有边界检查,因此它一定比 __insertion_sort 要快。但由于 __unguarded_insertion_sort_aux 会从 first 开始调用 __unguarded_linear_insert;因此使用 __unguarded_insertion_sort 的条件比 __unguarded_linear_insert 更加严格。它必须保证以下假设成立:在 first 左边的有效位置上,存在不大于 [first, last) 中所有元素的元素。
回答三个问题
至此我们可以回答第一个问题:
__insertion_sort实现了标准的插入排序的功能。但由于内部使用了__linear_insert和__unguarded_linear_insert内部函数,其效率比标准的插入排序效率要高。__unguarded_insertion_sort基本上也实现了插入排序的思想,但它实现的功能比标准的插入排序稍弱。它要求在first左边的有效位置上,存在不大于[first, last)中所有元素的元素。
以及我们可以部分回答第二个问题:
__unguarded_insertion_sort的效率比__insertion_sort高,因此我们应该尽可能对更多的元素使用__unguarded_insertion_sort。但使用它是有前提的,因此至少对最头部的一些元素,我们不能使用__unguarded_insertion_sort。- 但这只是部分回答了第二个问题;因为我们仍然没有说明为什么对头部
__stl_threshold个元素之外的元素使用__unguarded_insertion_sort是安全的。也即我们需要证明:头部__stl_threshold个元素中一定存在不小于区间[first + __stl_threshold, last)中所有元素的元素。
以及我们可以回答第三个问题:
- 若
last - first > __stl_threshold不成立,则事实上__introsort_loop不会对序列做任何实际操作——这是由内省式排序while循环的条件确保的。这种情况下,不能使用__unguarded_insertion_sort,而是要使用具有完整排序能力的__insertion_sort来执行最终的插入排序操作。
完整回答第二个问题
至此,我们唯独遗留的问题是要证明:头部 __stl_threshold 个元素中一定存在不小于区间 [first + __stl_threshold, last) 中所有元素的元素。
由于 __final_insertion_sort 在 __introsort_loop 之后调用,这个问题某种程度上是显然的。考虑 __introsort_loop 的两个退出条件,然后分类讨论:
- 因递归切分,导致
last - first > __stl_threshold不成立而退出。 - 因递归过深,调用堆排序而退出。
对第一种情况,考虑快排特性可知,最左侧的 [first, last) 区间的所有元素,都不大于右侧所有元素。又因为 last - first <= __stl_threshold,因此在 [first, first + __stl_threshold) 中必然存在一个元素,不大于 [first + __stl_threshold, last) 中的所有元素。
对第二种情况,同样考虑快排特性,最左侧的 [first, last) 区间的所有元素,都不大于右侧所有元素。尽管此时不一定成立 last - first <= __stl_threshold,但堆排保证了 first 元素是该区间内值最小的元素。因此至少它不大于 [first + __stl_threshold, last) 中的所有元素。
因此我们说,经过 __introsort_loop 之后,头部 __stl_threshold 个元素中一定存在不小于区间 [first + __stl_threshold, last) 中所有元素的元素。
结语
纵观整个 std::sort 的实现,可以看到很多为了效率,而无所不用其极地对代码进行精雕细琢。作为程序员,相信没有人能对这种精湛技艺熟视无睹。欣赏 STL 代码时,我们一方面需要去理解这样做为什么是对的,还要去理解这样做为什么能提高效率。如此,才能真正吃透 STL 的代码,并能有自己的收获。


