最近在阅读 Airbnb 的论文 Applying Deep Learning to Airbnb Search。阅读的过程中,我发现作者在谈及特征归一化的必要性时,有如下表述:
Feeding values that are outside the usual range of features can cause large gradients to back propagate. This can permanently shut of activation functions like ReLU due to vanishing gradients.
翻译成中文:
神经网络接受异于常值范围的输入时,在反向传播过程中会产生大的梯度。这种大的梯度,会因梯度消失而永久关闭诸如 ReLU 的激活函数。
我感到有些疑惑。ReLU 正是为了解决梯度消失问题而设计的。为什么这里会提到「因梯度消失而永久关闭诸如 ReLU 的激活函数」呢?
此篇来讨论这个问题。
ReLU 函数
ReLU 的全称是 Rectified Linear Unit,即:线性整流单元。对于输入 $x$,它有输出
$$y = \max(0, x).$$
相应地,有导数
$$y' = \begin{cases}1 & x > 0, \\ 0 & x < 0.\end{cases}$$
由于 ReLU 在 $x > 0$ 时,导数恒为 1。因此在反向传播的过程中,不会因为导数连乘,而使得梯度特别小,以至于参数无法更新。在这个意义上,ReLU 确实避免了梯度消失问题。
异常输入杀死神经元
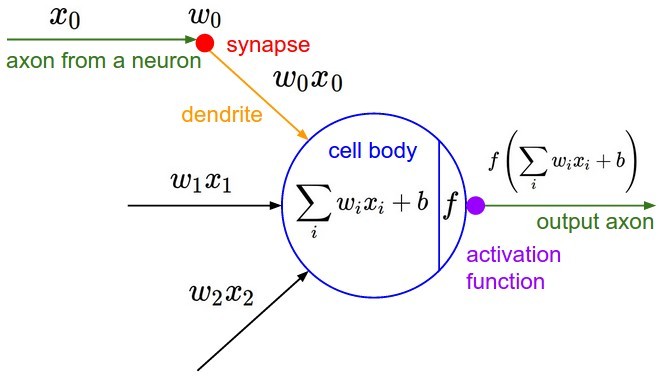
上图是一个典型的神经元。
现在假设,这个神经元已经经过若干次迭代,其参数 $(\vec w, b)$ 已经迭代得趋于稳定。现在,神经元接收到了一个异常的输入 $\vec x$。比方说,它的某一维特征 $x_i$ 与对应的权重 $w_i$ 的乘积 $w_ix_i$ 非常大。一般来说,这意味着 $x_i$ 的绝对值非常大。于是,ReLU 的输入就会很大,对应 ReLU 的输出 $y$ 也就会很大。好了,假设这个 ReLU 神经元期望的输出(ground truth)是 $\hat y$,这个时候损失就会很大——损失一般是 $\lvert y - \hat y\rvert$ 的增函数,记为 $f\bigl(\lvert y - \hat y\rvert\bigr)$。
于是,在反向传播过程中,传递到 ReLU 的输入时的梯度就是 $g = f\bigl(\lvert y - \hat y\rvert\bigr)$。考虑对于偏置 $b$ 有更新
$$b \gets b - g\eta.$$
考虑到 $g$ 是一个很大的正数,于是 $b$ 可能被更新为一个很小的负数。此后,对于常规输入来说,ReLU 的输入大概率是个负数。这也就是说,ReLU 大概率是关闭的。这时,梯度无法经 ReLU 反向传播至 ReLU 的输入函数。也就是说,这个神经元的参数再也不会更新了。这就是所谓的「神经元死亡」。
如此看来,尽管 ReLU 解决了因激活函数导数的绝对值小于 1,在反向传播连乘的过程中迅速变小消失至 0 的问题,但由于它在输入为负的区段导数恒为零,而使得它对异常值特别敏感。这种异常值可能会使 ReLU 永久关闭,而杀死神经元。
梯度消失?
梯度消失(gradient vanishing)是深度神经网络中的一种现象。导致它的原因有很多。由于激活函数导数连乘导致的梯度消失问题最为出名。因此,在很多人心里(包括我过去也是),梯度消失指得就是这种现象。故而对原文的表述有困惑。这种理解实际上是一种不完全的、很偷懒的做法。因此,对概念的理解要着重深入到实际情况中去,而不能囫囵吞枣。
共勉。


