Linux 系统中,著名的 top 命令可列出各个进程对系统资源的利用情况。其中有 VIRT, RES, SHR, CODE, DATA 等几个字段,用来描述进程对内存的使用情况。(后二者默认不展示,需要按下 F 键,将相关字段调出来)。
但它们究竟表示什么含义呢?
top 命令的文档
执行 man top 可查看 top 命令的手册。可见这些字段的含义:
VIRTVirtual Memory Size (KiB):进程使用的所有虚拟内存;包括代码(code)、数据(data)、共享库(shared libraries),以及被换出(swap out)到交换区和映射了(map)但尚未使用(未载入实体内存)的部分。RESResident Memory Size (KiB):进程所占用的所有实体内存(physical memory),不包括被换出到交换区的部分。SHRShared Memory Size (KiB):进程可读的全部共享内存,并非所有部分都包含在RES中。它反映了可能被其他进程共享的内存部分。CODECode Size (KiB):进程所占用的实体内存中,可执行代码所占用的内存大小。此项亦称为驻存代码集合(Text Resident Set, TRS)。DATAData + Stack Size (KiB):进程所占用的实体内存中,除去可执行代码所占用部分之外的内存大小。此项亦称为驻存数据集合(Data Resident Set, DRS)。
但是,真的这样吗?
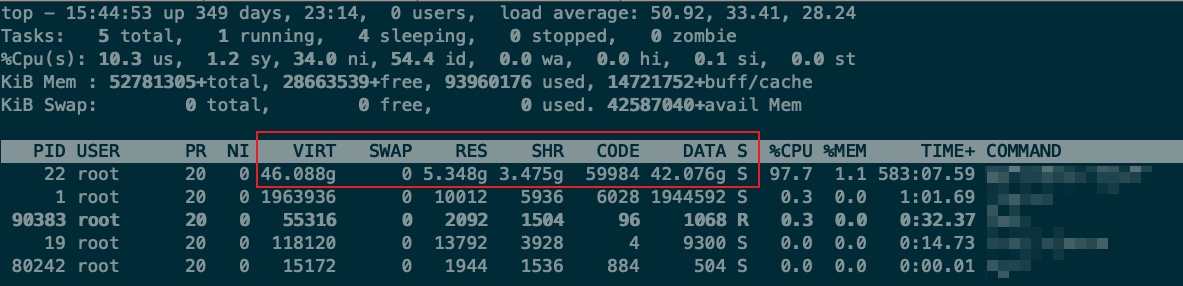
按照 top 命令的手册,应有等式 CODE + DATA = RES 成立。但这里,进程号为 22 的进程,CODE 为 59,984KiB,DATA 为 42.076GiB,RES 为 5.348GiB。显然不满足上述等式。
top 命令的数据源
经查,top 命令读取的是 /proc/<pid>/statm 当中的数据。
你可以通过
cat /proc/<pid>/statm来查看。它有 7 列,分别是以内存页计算的VIRT,RES,SHR,CODE, LRS,DATA, DIRTY。其中 LRS 和 DIRTY 自 Linux 2.6 开始不再使用。内存页的大小是 4KiB,因此,将内存页的数量乘以 4,就是以 KiB 计算的内存占用大小。
而 /proc/<pid>/statm 当中的数据,是经过内核函数 task_statm 读取而后由 procfs 写入的。
我们来看看内核函数 task_statm 是怎样定义的:
1 | unsigned long task_statm(struct mm_struct *mm, |
这里 get_mm_counter 实际啥也没干,就是保证读取计数器的原子性——这是因为读取的是实体内存占用情况。
由此可知,并不一定有等式 CODE + DATA = RES 成立,但一定成立等式 ANON = RES - SHR。这里 ANON 表示在堆上分配的内存。
2
3
4
5
6
7
8
9
10
11
12
13
14
{
long val = atomic_long_read(&mm->rss_stat.count[member]);
/*
* counter is updated in asynchronous manner and may go to minus.
* But it's never be expected number for users.
*/
if (val < 0)
val = 0;
return (unsigned long)val;
}可见
get_mm_counter其实啥也没干,就是保证读取计数器的原子性。
从代码可见
shared是共享文件和动态库占用实体内存页(memory page)之和;它对应SHR。text是代码段占用内存页;它对应CODE。data是VM_WRITE & ~VM_SHARED & ~VM_STACK与VM_STACK占用内存页之和,也就是所有非栈内存中可写但非共享内存页与栈内存页之和;它对应DATA。resident是shared和实体匿名内存页(memory page)之和;它对应RES。- return value 是整个虚拟内存的内存页;它对应
VIRT。
从代码来看,VIRT, SHR, CODE, RES 与 top 命令的手册吻合,区别在于 DATA 这个字段——从我们观察到的现象,也确实在 DATA 上有明显的问题。
DATA 之谜
在老文中,我们谈到了虚拟内存和物理内存(实体内存)之间的差别与联系。在 Linux 中,进程能直接看到的,都是虚拟内存。
对于每一个虚拟内存页,根据其是否有对应的实体内存帧对应,有三种状态:
- 该页没有实体内存帧与之对应;记为 vm_unmapped。
- 该页有实体内存帧与之对应,且未被换出到交换区;记为 vm_physic。
- 该页有实体内存帧与之对应,但已被换出到交换区;记为 vm_swap。
在本文讨论的五个字段当中,按照是否有强调为 vm_physic,记录如下:
top 手册 |
内核代码 | |
|---|---|---|
VIRT |
x | x |
RES |
y | y |
SHR |
x | y |
CODE |
y | y |
DATA |
y | x |
可见,比较明确的是 VIRT, RES 和 CODE。SHR 的情况也比较好理解,内核代码可以明确是只包含实体内存部分,而 top 手册里则没有说明,因此我们也将其理解为只包含实体内存部分。
现在,需要确认的,就是 DATA 了。我们看一下 DATA 的实现:
1 | *data = mm->data_vm + mm->stack_vm; |
其中 mm 是 Linux 的内存描述符,它定义在 linux/mm_types.h 当中,是一个相当大的结构体。其中 data_vm 和 stack_vm 的定义如下:
1 | unsigned long data_vm; /* VM_WRITE & ~VM_SHARED & ~VM_STACK */ |
这里,显然后缀 vm 表示虚拟内存(Virtual Memory),因此 DATA 表示的不只是实体内存占用,这一点是显然的了。接下来的问题是,这里的注释表示什么呢?VM_WRITE 等宏,定义在 linux/mm.h 当中。这些宏表示虚拟内存区域(Virtual Memory Area, vm_area)的属性,由一些 one-hot 的整数来表示。于是,VM_WRITE & ~VM_SHARED & ~VM_STACK 表示非栈且非共享的可写虚拟内存区域。因此 DATA 字段表达的是虚拟内存中,栈区域与非栈区域中非共享可写区域之和。
这也就能解释,为什么 DATA 看起来远远大于 RES 了。因为 RES 是实际占用的实体内存大小,而 DATA 计算的是数据部分占用虚拟内存的大小。后者可能包含了大量实际没有与实体内存帧映射的虚拟内存页,从而导致看起来虚高。
总结
top 的手册关于 DATA 的说明是错的,有 bug。更新如下:
VIRTVirtual Memory Size (KiB):进程使用的所有虚拟内存;包括代码(code)、数据(data)、共享库(shared libraries),以及被换出(swap out)到交换区和映射了(map)但尚未使用(未载入实体内存)的部分。RESResident Memory Size (KiB):进程所占用的所有实体内存(physical memory),不包括被换出到交换区的部分。SHRShared Memory Size (KiB):进程可读的全部共享实体内存,并非所有部分都包含在RES中。它反映了可能被其他进程共享的内存部分。CODECode Size (KiB):进程所占用的实体内存中,可执行代码所占用的内存大小。此项亦称为驻存代码集合(Text Resident Set, TRS)。DATAData + Stack Size (KiB):进程所占用的虚拟内存中,栈区域与非栈区域中非共享可写区域之和。
不一定有等式 CODE + DATA = RES 成立,但一定成立等式 ANON = RES - SHR 及不等式 ANON <= DATA (vm_physic) <= DATA。如果观察到程序稳定运行时 RES - SHR 不断增长,则可能预示着程序存在内存泄漏现象。


